
minzzl
TCP의 window based Flow Contorl (흐름제어) 본문
TCP(Transmission Control Protocol)

TCP는 OSI 7 layer 중 4 계층에 속하는 중요 프로토콜로 네트워크 망에 연결된 컴퓨터의 프로그램 간의 데이터를 순서대로, 에러없이 교환할 수 있게 해줍니다.
그렇다면 TCP는 어떤 특징을 가지고 있을까요?
특징은 다음과 같습니다.
- 연결 지향 프로토콜
- 신뢰할 수 있는 프로토콜
TCP는 연결 지향형 프로토콜로, 물리적으로 전용 회선이 연결되어 있는 것처럼 가상의 연결통로를 설정하여 통신하는 방식으로 동작합니다. 이 때 가상의 연결 통로를 가상 회선이라고 합니다. 이러한 논리적인 연결통로를 통해 데이터를 주고 받음으로서 데이터의 전송 순서를 보장합니다.(순서 제어) 이 때 가상 회선을 통해, 데이터를 임의의 크기로 나누어 연속해서 데이터를 전송하는, 스트림 기반의 전송 방식을 사용합니다.
또한 신뢰성을 보장하기 위해,
흐름제어, 오류제어, 혼잡제어를 제공합니다.
여기서 잠깐, TCP에서 신뢰성을 제공하는 이유는 .. 무엇일까요?
우리는 Physical layer, Data link layer, Network layer 를 거쳐서 Transport layer에 다다르게 됩니다. Transport layer의 대표적인 프로토콜이 TCP 이구요. Physical layer는 전송 회선에 대한 프로토콜, Data link layer는 그 전송 회선을 타고 옆 노드(컴퓨터 등)로 어떻게 상대방이 알아들을 수 있도록 잘 전달할 것인가에 대한 프로토콜, Nerwork layer는 바로 옆이 아닌 저 멀리에 있는 컴퓨터로 어떻게 보낼 수 있을지에 대한 프로토콜이었습니다. 특히나 Network layer인 IP 를 거친 패킷들은 아주 엉망징창일지도 모릅니다. 그래서 TCP 에서 다시 한번, 신뢰할 수 있는 데이터 수집을 위해 다음과 같은 제어를 사용합니다.
1) 흐름 제어: 상대방이 받을 수 있는 만큼만 데이터를 효율적으로 전송
흐름제어를 위해 sliding window 방식을 사용합니다. 이는 상대방이 수신 가능한 크기인 window size 내에서 데이터를 연속으로 전송하는 방식입니다.

매 세그먼트마다 수신 확인 응답(ACK)를 수신한 후 전송하게되면 왕복 시간(RTT)가 매우 길어져 데이터의 전송량이 매우 낮아지기 때문에, 이를 효율적으로 하기 위해 상대방이 받을 수 있는 범위 내에서 연속적으로 전송합니다.
2) 오류제어:
데이터의 오류나 누락없이 안전한 전송을 보장하기 위한 제어입니다. 오류나 누락 발생시 재전송합니다.
3) 혼잡제어:
네트워크의 혼잡 정도에 따라, 송신자가 데이터 전송량을 제어하는 것을 의미합니다. 혼잡의 판단 기준은 데이터의 손실 유무로 판단하며 전송한 데이터에 누락이 발생할 경우 네트워크가 혼잡한 상태로 판단하여 전송량을 조절합니다.
우리는 오늘 그 중, TCP의 흐름제어에 대해 알아보겠습니다.
다시 한번, 흐름제어란 송신측과 수신측의 속도를 맞추기 위한 기법으로 송신측의 전송속도를 수신측에 맞추어 조절하게됩니다.
수신측의 속도가 송신측보다 빠른 경우라면 문제 될 것이 없습니다. 송신측이 늦게보내더라도 수신측이 빠르게 데이터를 처리하니.. 그냥 효율이 떨어진다뿐이지 어떠한 데이터 누락으로 재전송하는 일은 없으니까요. 그러나 그 반대의 경우라면 수신측에서 저장용량이 초과되거나, 지연등이 일어날경우 불필요한 통신과 처리과정이 동반될 것입니다.
앞서 말했듯, TCP는 데이터의 신뢰성을 보장합니다. 이는 전송된 패킷에 대한 ACK 응답을 통해 이루어집니다.
이 ACK 응답을 이용해 하나의 프레임을 전송하고 ACK를 기다리고 응답을 받으면 다음 프레임을 전송하는 식으로 한번에 하나의 프레임을 전송하는 식으로 제어하는 방식을 Stop-And-Wait라고합니다. 그런데 이 방식은 단순하고 오버플로우가 일어나지는 않지만, 빈번한 통신으로 느리다는 단점이 있습니다.
이를 개선한 방법이 Sliding window입니다.
위에서도 설명했지만, Sliding window를 통해 수신측에서 설정한 window 만큼 송신측에서 ACK 응답 없이 전송할 수 있게 하여 데이터 흐름을 동적으로 조절할 수 있습니다. 이는 윈도우에 포함되는 모든 패킷을 전송하고 그 패킷들의 전달이 확인되는대로 이 윈도우를 옆으로 옮겨(Slide) 그 다음 패킷들을 전송해 윈도우의 크기만큼은 수신쪽의 ACK 응답을 받지 않고도 보내는 것이 가능하므로 Stop-And-Wait보다 효율적입니다. 윈도우의 크기는 연결시에 수신측의 윈도우 사이즈에 송신측의 윈도우 사이즈를 맞춥니다.
호스트들은 실제 데이터를 보내기 전인, 3-way-handshake를 통해, 수신 컴퓨터의 recieve window size에 자신의 send window size를 맞추게 됩니다. 상대방이 받을 수 있는 크기에 맞추어 전송하는 것(흐름제어)입니다.
A가 B에게 10kbyte를 전송한다고 했을 때를 가정해봅시다.
window 사이즈는 8K, TCP segment 1K일 때를 나타내면 다음과 같습니다.

그림처럼, 호스트는 자신이 보내야할 전체 데이터 중, 사용가능한 윈도우 사이즈만큼 데이터를 전송합니다. 위에서 window size가 8K라고 했으니, 1번부터 8번까지 순차적으로 데이터를 내보낼 수 있습니다. 그 이후에 상대방의 응답을 기다립니다. 또한 Ack 신호가 오면 window를 slide 시켜 다음 순서의 TCP segment를 전송합니다.
그런데 만약, 수신측의 입장에서 1번과 3번 패킷이 도착했지만, 2번이 아직 도착하지 않았다면 어떻게 될까요?
TCP는 1,2 혹은 2,3 과 같이 2개 이상의 연속된 패킷이 도착하면 새로운 패킷을 전송한다는 약속을 해두었기에 기다려야만합니다. 그래서 이를 위한 해결책이 있습니다. 받는 측의 컴퓨터는 패킷이 도착했을 때, Delay Acknowledge Timer 라고 부르는 Timer를 설치해둡니다. 이 Timer의 시간이 만료될 때까지 2번 패킷이 도착하지 않는 다면 받은 1번 패킷에 대한 Ack 신로만이라도 전송해줍니다.
또한 송신측의 입장에서, Ack를 못받았다면 어떻게 해야할까요? 이러한 문제를 해결하기 위해 송신 컴퓨터의 TCP는 자신이 보낼 수 있는 Window size 만큼 데이터를 전송하고 자신이 보낸 데이터에 대해서 각 segment 마다 retransmission timer 라고 하는 timer를 설피합니다. 만일 이 timer 시간이 만료될 때까지 Ack가 도착하지 않으면 재전송을 합니다.
결혼적으로 TCP는 window size를 이용해서 한꺼번에 일정량의 데이터를 전송하며, 이를 효율적으로 하기 위해 sliding window 방식을 사용합니다. 또한 여기에서 비롯될 수 있는 문제들을 위해 Delay Acknowledge Timer, Retransmission Timer를 이용해서 대비책을 마련해둡니다.
사실 흐름 제어를 살표보고자 한 이유는 Window 개념을 소개하기 위해서 입니다.
Window
위에서 확인 한 것처럼 window는 TCP 송신자가 수신자의 확인 없이도 한번에 보낼 수 있는 data 양입니다.
사실 TCP에서 window라는 용어는 빈번하게 사용됩니다. TCP는 window based flow control, window based congestion control을 합니다. 또한 sliding window, reciever window, send window. congestion window 와 같이 아주 다양하게 사용이 딥니다.
즉 TCP에서 window는 어떤 일정 양의 데이터를 의미하는데, window 라는 용어를 들어서는 와닿지 않습니다.
그래서 TCP 동작 방식에 대해서 살펴 보면서, TCP에서 window가 각각의 영우에서 어떤 개념으로 사용되는지 알아보겠습니다.
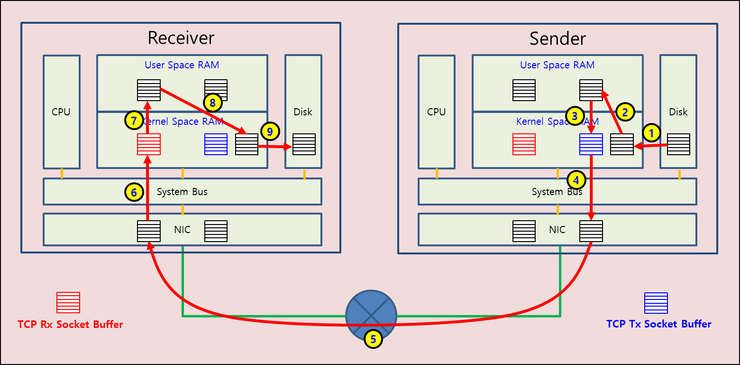
위의 그림은 실제 컴퓨터 시스템에서 데이터가 어떻게 이동하는지, window based flow control이나, window based congestion control 등이 어떻게 동작하는지 이미지화 한 그림입니다.
그렇다면 컴퓨터 네트워크에서 데이터가 어떻게 이동하는지 살펴보겠습니다.
Sender의 Disk에 있는 데이터를 FTP를 이용해서 Receiver의 Disk로 내려받는 경우를 가정해봅시다.
1) User Space에서 동작하는 FTP Application은 Disk에 있는 데이터를 읽어서 네트워크로 전송하기 위해서 read() system call을 사용하면, FTP Application에서 커널 Task로 Context Switching이 일어나서 커널에서 Disk에 있는 데이터를 커널 메모리 Buffer로 읽어들입니다.
2) copy_to_user() 함수를 이용해서 커널 메모리에 읽어 들인 데이터가 User Space의 buffer 메모리로 copy되고, FTP Application으로 Context Switching이 일어납니다.
3) FTP Appliation이 send(), send_to(), write() 등의 함수를 이용해서 Disk에서 읽어온 데이터를 네트워크로 내 보내고자 전송을 시도하면, FTP Application에서 커널 Task로 Context switching이 일어나서 커널에서 copy_from_user 함수를 이용하여 사용자 공간에 있는 데이터를 커널에 있는 TCP Tx Socket Buffer로 copy합니다.
4) data의 size가 TCP MSS(Maximum Segment Size)보다 작으면 TCP header를 추가해서 IP layer 함수를 호출하고, data size가 TCP MSS보다 크면, data를 MSS size로 자르고, 잘라진 각각의 TCP segment에 header를 추가하여, 각 segment 순서로 IP layer 함수를 호출합니다. 커널 스택의 IP layer, MAC Layer 함수를 거친 데이터는 커널 메모리에서 NIC buffer 메모리로 copy 됩니다.
5) Sender NIC에서 전송된 data는 네트워크에 존재하는 라우터, 스위치, 방화벽, AP 등을 통과해서 Reciever NIC으로 전달됩니다.
6) NIC buffer 메모리에 수신된 데이터는 Interrupt 방식 혹은 polling 방식에 의해서 커널 TCP Rx Socker buffer로 copy 됩니다.
7) FTP Application 에서는 recv() 또는 read() 함수를 이용해서 네트워크에서 데이터가 수신되면 읽어들이는데이 함수들은 blocking 모드 상태로 데이터가 buffer에 들어오기를 기다리게 됩니다. 커널의 TCP layer에서는 user data가 Rx Socker buffer에 도착해 있으면 copy_to_user 함수를 이용해서 데이터는 user 메모리 공간으로 복사하고, FTP application을 깨워 데이터를 읽어가도록 합니다. Application에서 recv()나 read()를 이용해서 데이터를 읽어가고자 하지 않으면, TCP layer에서는 Rx Socket Buffer의 data를 User application으로 전달할 수 없습니다.
8)FTP Apllication은 수신된 data를 로컬 buffer에서 write() 함수를 이용해서 local disk에 저장합니다. 이때 write 함수는 user contest에서 커널 context로 Context Switching이 일어납니다. 커널 Task에서는 copy_from_user() 함수를 이용해서 data 를 커널 메모리 공간으로 copy gkqslekl
9)커널에서 disk에 data를 write 합니다.
송신자는 보내고, 수신자는 받는다!
TCP를 이용한 네트워크 통신은 저희가 보통 처음 배우기를, Server - Client 방식으로 배웁니다.
서버는 Client의 접속을 기다리고,
Client가 접속을 시도하면 접속이 된 이후에 data의 송수신이 이루어집니다.
언뜻 생각하기에 서버는 보내기만 하고, 클라이언트는 받기만 할 것같은 생각이 들지만 아닙니다.
서버에서 클라이언트로 데이터를 보내는 경우를 Download , 클라이언트에서 서버로 데이터를 보내는 경우를 Upload 라고 합니다.
Download 의 경우 서버가 송신자가 되고, 클라이언트는 수신자가 됩니다.
반대로 Upload는 클라이언트가 송신자가 되고 서버가 수신자가 됩니다,
이렇게 TCP는 송신자와 수신자가 서로 데이터를 주고 받습니다.
그렇다면, TCP와 자주 비교가 되는 UDP를 이용하는 경우는 어떨까요?
UDP도 송신자가 데이터를 보내고, 수신자가 데이터를 받습니다. UDP도 위의 그림과 크게 다르지 않습니다. 그러나 TCP는 데이터가 수신자에게 잘 전달되었는지 ACK를 보내서 알려주지만, UDP는 아닙니다. 그렇기 떄문에 TCP는 송신자가 ACK를 받지 못하는 경우 data가 어딘가 유실된 것으로 판단하고 재전송을 해주어 수신자에게 신뢰성을 보장하지만 UDP는 그러한 매커니즘이 없습니다. 그렇게 때문에 UDP를 사용하는 Applicaion은 데이터 수신을 확실하게 보장해야하는 경우, Application layer에서 재전송 매커니즘을 구현해야합니다.
송신자가 ACK 없이 최대로 보낼 수 있는 데이터 Byte의 수
앞서 TCP는 송신자가 데이터를 전송한 후, 수신자에게 데이터를 잘 받았는지에 대한 여부를 수신자가 보낸 ACK를 통해서 알 수 있다고 말씀드렸습니다. 그렇다면 데이터의 뭉치가 있을 때는 어떻게 데이터를 보내고 ACK를 받는 것일까요? 각각의 데이터를 보낼 때 마다, 그 전의 데이터를 수신자가 잘 받았는지에 대한 ACK를 받아야만 그 다음데이터를 보낼 수 있을까요? 정답은 .. 아닙니다! 송신자가, 수신자로 부터의 ACK 없이 한번에 최대로 여러개의 데이터의 뭉치를 보낼 수 있는 양이 지정이 되어 있습니다. 이 값은 송신자가 관리하는 Software parameter로, 고정된 값이 아니며, 네트워크 상황에 따라 지속적으로 변합니다. 즉 .. 어떤 안정된 네트워크 상황에서는 고정된 값으로 수렴할 수도, 망의 상황에 의해 지속적으로 변할 수도 있습니다.
그럼 다시 위의 그림 이야기를 해봅시다.
우리는 앞서 User Application 으로부터 TCP Tc Socket Buffer에 들어온 데이터를 TCP는 MSS 라고 하는 TCP 최대 파켓 크기로 잘라서 TCP MSS라고 하는 TCP 최대 패킷 크기로 잘라서 TCP 헤더를 붙이고, IP 계층 함수를 호출해서 데이터가 네트워크로 전송되도록 합니다. User Application으로 부터 TCP Tx Socket 버퍼로 한번에 들어올 수 있는 최대 데이터의 크기는 64KB 입니다. (사실 .. IPv6에서는 큰 데이터가 넘어올 수도 있습니다..) UDP도 동일하게 User Application으로부터 UDP Tx Socket Buffer로 한번에 들어올 수 있는 최대 데이터그램의 크기는 64KB입니다. UDP는 TCP가 user application으로부터 전달받은 데이터를 MSS 크기로 잘라서 보내는 것과 다르게 그냥 user application에서 받은 그대로 IP 계층으로 내려보냅니다. UDP나 TCP 모두 IP 계층을 거쳐서 Ethernet으로 전송이 되게 되는데, Ethermet의 MTU는 표준인 1500Byte로 같습니다. IP header(20Byte)를 포함해서 한번에 보낼 수 있는 최대 크기가 1500 Bytedlrl Eoansdp 1480 byte보다 큰 UDP datagram이나 TCP segment는 IP 계층에서 fragmentation 되어 전송됩니다. UDP는 UDP 계층에서 데이터 가공 없이 그냥 IP 계층으로 내려 보내기 때문에 1480 Byte에서 UDP header 8Byte를 제외한 1472 byte보다 큰 데이터가 user application 에서 UDP로 내랴오면 그대로 IP 게층으로 전달하게 되고 이 경우 IP 계층에서 Fragmenation이 발생하여 여러개의 IP 패킷으로 나뉘어져 보내지게 됩니다. TCP는 위에서 말씀드린 바와 같이 TCP 계층에서 MSS 라고 하는 TCP 최대 패킷 크기로 잘라서 TCP header(20bytes)를 붙여서 IP 계층으로 보냅니다.

MSS (Maximum Segment Size)
MSS는 TCP Connection이 맺어지는 3 way handshake 단계에서 SYN/ACK 패킷에 option으로 TCP sender와 reciever가 서로 주고 받습니다. 이렇게 주고 받은 MSS에서 더 작은 값이 양쪽 Sender와 Reciver에서 모두 MSS 값으로 사용됩니다.

TCP가 option으로 주고 받는 MSS는 Ethernet MTU에 맞추어서 IP Fragmentation이 발생하지 않는 크기를 서로 교환하기 때문에, 일반적으로 host에서 IP fragmentation이 발생하지 않습니다. 일반적으로 (Ipv4) IP header 20 byte와 TCP header 20 byte를 제외학 1460 byte가 MSS로 사용됩니다.
근데 여기서 의문이 드실지도 모릅니다. UDP는 데이터를 잘라서 보내지 않는데, 왜 TCP는 직접 데이터를 잘라서 보내게 했을까요 .!?
그것은 바로 ! 재전송을 위해서입니다.
만일 TCP가 user application에서 받은 64KB의 데이터를 MSS 크기 만큼 자르지 않고 그대로 보낸다면, IP 계층에서 fragmentation이 되어 packet들이 전송 될 것입니다. 이 경우 만일 네트워크에서 패킷이 유실될 경우를 가정해보면, TCP에서 신뢰성있는 전송을 위해 재전송을 해주어야하는데, 네트워크에서 fragmentation 된 1개의 패킷이 유실되더라도 TCP 계층에서는 그것을 알 수가 없어 64KB를 다시 전송해주어야합니다. 이것은 굉장히 비효율적입니다. 그래서 TCP는 segment 단위로 잘라서 보내고, segment 마다 sequence number를 부여해서 보냅니다. 네트워크에서 segment가 유실되더라도 sequence number를 이용해서 해당 segment만 다시 재전송해줄 수 있습니다. MSS는 설명드릴 것 처럼 TCP 계층에서 IP Fragmentation이 발생하지 않도록 Ethernet MTU에 맞추어 재단하는 최대 크기일뿐 TCP window와는 상관이 없습니다.
언제 다보내지..
보내야할 데이터가 있을때. 한번에 보내는 양이 작으면 총 데이터를 받는데까지의 속도는 느려질 것이고,
한번에 보낼 수 있는 양이 크다면 전잡다는 훨씬 속도가 빨라질 것입니다.
TCP는 신뢰성있는 전송을 위해서 수신자가 받은 것은 송신자에게 ACK로 알려줍니다. 그런데 만일 매 하나의 패킷마다 ACK를 받은 후 다음 패킷을 보낸다면 속도는 현저히 느릴 것입니다.
송신자와 수신자의 거리가 매우 가까운 경우라면 상관이 없을 수도 있겠지만 거리가 멀어질 수도 속도는 더욱 현저하게 느려집니다.
RTT는 물리적인 거리에 의해 지연이 발생하는 것은 자명합니다. 즉 지역적으로 클라이언트와 서버가 멀리 떨어진 곳에 있다면 RTT는 매우 커집니다.

그렇다면, 이러한, 우리가 어떻게 할 수 없는 물리적인 지연을 건드리는 것말고는 어떻게 하면 속도를 개선할 수 있을까요?
네, 그냥 한번에 최대한 많이 보내면 됩니다.
위에서 말씀드렸던 Tx Window의 크기를 크게 하면됩니다.
우선 헷갈릴 수 있으니 여러가지 window들을 다시한번 짚어보겠습니다.
- Recieve Window : 수신자가 송신자에게 알려주는, 현재 수신 가능한 비어있는 Rx Socket 버퍼크기
- Send Window : 송신자가 수신자의 ACK 없이 한번에 전송할 수 있는 데이터 양
- Window Scaling : 2Byte로 고정된 Window size제약을 극복하기 위해서 사용하는 TCP option
- Sliding Window : 송신자가 수신자의 Rx socket buffer overflow가 발생되지 않도록 전송량을 control 하는 매커니즘
- Window Full : Wire shark가 보여주는 분석 정보의 하나로 송신자가 수신자 ACK 없이 보낼 수 있는 데이터를 모두 보냈음을 의미
- Zero Window : 수신자의 Rx Socket buffer가 꽉찰 것 같은 상황이 닥치면 수신자는 Window Size를 0으로 채워 보냄
- Congestion WIndow: Network congestoin 발생시 network 부하를 감소시키기 위해서 사용하는 송신자의 window
- Window based flow control : 수신자의 Rx Socket Buffer overflow가 발생되지 않도록 송신자의 전송량을 control 하는 매커니즘
- Window based congestion control : 송신자와 수신자의 네트워크에서 congestion을 회피하기 위해 사용하는 매커니즘
+ Buffer overflow : buffer 에 저장공간이 꽉차서 새로이 도착하는 데이터가 버려지는 것을 buffer overflow가 발생한다고 이야기함
어떻게 Window size를 키우지?

다시 한번, 이 그림을 살펴보겠습니다.
파란색으로 표시된 Tx socket Buffer가 꽉차 있다면 User Application은 TCP 계층으로 데이터를 내려보낼 수 없습니다.
또한 NIC의 Buffer가 꽉 차 있으면, Tx Socket Buffer의 데이터를 NIC buffer로 보낼 수 없습니다.
뿐만아니라 빨간색으로 표시도니 Rx buffer가 꽉차있으면 NIC buffer의 데이터를 Rx Socket buffer로 보낼 수 없습니다.
그리고 User application 이 Rx Socket buffer의 데이터를 읽어가지 않거나, 읽어가는 속도가, NIC 버퍼로 새로운 데이터가 들어오는 속도보다 늦으면 Rx Socket Buffer는 꽉채워질 수 있습니다.
수신자의 Rx Socket Buffer가 꽉채워지게 되면 더 이상 데이터를 받아 들일 수 없으므로 새로이 도착하는 데이터들은 유실될 수 밖에 없습니다. 이런 상황, 즉 수신자의 Rx Socket Buffer overflow가 발생하는 상황을 방지하기 위해서 TCP가 사용하는 매커니즘이 Flow Control 입니다.
맨 위에서 Flow Control 에 대해 설명했습니다. 수신자는 TCP Rx Socket Buffer의 빈공간 크기를 송신자에게 알려주고, 송신자는 그 빈공간 크기가 넘치치 않을 만큼만 계산해서 데이터를 전송하고 추가적인 데이터를 전송하기 위해서 수신자의 ACK를 기다립니다. TCP 송신자와 수신자가 주고 받는 모든 패킷의 헤더에는 Window Size 필드가 있어서 이 필드를 이용해서 Rx Socket Buffer의 여유 공간의 크기를 상대편에게 알려줍니다.

만일 Rx Socket Buffer가 꽉차게 될 상황일 경우, 수신자는 Zero window 를 보내고 , Zero window를 받은 송신자는 수신자로부터 다시 데이터를 보내도 좋다는 다른 세그먼크를 받으면 다시 데이터를 전송할 수 있습니다. 이처럼 수신자의 window size를 송신자에게 알려서 송신자가 수신자의 Buffer를 넘치지 않도록 데이터 전송을 Control 하는 것을 TCP에서는 Window based flow Control이라고 합니다.
Send Window ?
Recieve Window
Congestion WIndow
Retransmisson Queue
앞서 계속 이야기한 Recieve window의 값은 구하기 쉬운 값입니다.
수신자가 TCP Rx Socket Buffer의 여유 공간의 크기를 TCP header의 Window Size에 채워서 송신자에게 알려주는 것입니다.
이에 비해서 send window는 조금 어렵고 복잡합니다.
Send window는 TCP header에 알려주는 값이 아닙니다. 또한 TCP 송신자와 수신자가 주고 받는 패킷에 나오는 값도 아닙니다. 따라서 패킷 덤프를 받아서 wireshark로 본다고 해보 확인해볼 수 없는 값입니다.
Send window와 관련된 용어는 recieve window, congestion window, retransmission queue입니다. 네트워크 end to end 구간 어딘가에서 congestion이 발생해서 패킷이 유실되는 상황이거나 어떤 문제에 의해서 패킷이 유실되는 상황이 아니라면 send window는 recieve window와 같은 값입니다. 즉 수신자가 알려주는 recieve window를 그대로 send window로 사용합니다. 따라서 send window는 절대 recieve window보다 커질 수 없습니다. congestion이 발생하거나, 어떤 문제에 의해서 패킷이 유실되는 상황이라면 send window는 congestion window와 같은 값입니다.
Congestion window는 TCP 송신자가 관리하는 소프트웨어 값입니다. TCP는 패킷 유실 이벤트(TCP Time out, DUP_ACK 연속 3회 수신)가 감지되면, network에서 congestion이 발생한 것으로 판단하고 congestion window 값을 줄입니다. TCP session이 맺어진 이후에 패킷 유실이 없으면 congestion window는 recieve window와 같습니다. 패킷 유실이 발생하면 congestion window는 xongestion cotrol 알고리즘에 의해 감소하게 되고 TCP 송신자는 이 congestion window를 send window로 사용합니다. 사실 일반적인 네트워크 환경에서 congestion이 발생하지 않는 환경은 거의 없습니다. 따라서 일반적인 인터넷 환경에서 TCP session의 send window는 congestion window 값이 됩니다.
그렇다면 Retransmisson Queue는 어떻게 send window와 관련이 될까요?
Send window는 TCP 송신자가 수신자의 ACK 없이도 한번에 보낼 수 있는 최대 데이터 byte 양입니다. 그런데 만일 한번에 보낸 데이터 중 패킷 유실이 발생하면 송신자는 재전송을 해주어야합니다. 따라서 재전송을 위해서는 수진자의 ACK 없이 한번에 보낸 데이터는 수신자로 부터 ACK를 받기전에는 Retransmisson QUEUE에서 삭제할 수 없습니다. 즉 한번에 보낸 데이터는 Retransmisson queue에 저장되어 있어야하며 당연히 TCP 송신자는 Retransmission queue보다 큰 데이터를 한번에 보낼 수 없습니다. 즉 recieve window나 congestion window에 의해서 정해진 send window 값이 retransmission queue보다 크다 할지라도 TCP 송신자는 Retransmission QUEUE size 만큼만 수신자의 ACK 없이 한번에 보낼 수 있습니다.
사실 흐름제어는 End to End TCP 간에 벌어지는 일입니다.
즉, 양쪽 End인 TCP 송신자와 수신자 사이에 있는 중간 네트워크에서 벌어지는 일은 Flow Control과 전혀 무관합니다. Flow Control은 TCP 송신자와 수신자간에 벌어지는 일로 TCP 수신자의 Rx Socket Buffer가 꽉 차서 데이터가 버려지는 상황이 발생하지 않도록 데이터 전송을 Control 하는 매커니즘입니다.
Flow Control 을 각 용어들을 이용해서 단계적으로 설명해보겠습니다.
1) TCP 수신자는 Rx Socket buffer의 여유공간의 Recieve window로 ACK 패킷 헤더의 window size 필드에 해워서 보냄으로서 TCP 송신자에게 알린다.
2) TCP 송신자는 TCP 수신자가 통보해준 Recieve Window와 현재까지 보낸 데이터와 ACK를 이용해서 추가적으로 더 전송할 수 있는 데이터 양을 Sliding WIndow를 이용해서 계산하고, 추가로 전송할 수 있는 데이터가 있으면 데이터를 전송합니다.
3) TCP 속도를 높이기 위해서는 Window Size를 크게 할 수 있어야하는데, 2Byte로 할당된 TCP Window size 필드로는 64Kbytes가 최대이며 Window Scale 옵션을 사용하여 TCP Window Size를 크게 할 수 있습니다.
4) 수신자의 Rx Buffer 가 꽉 찰 상황이 다가오면 TCP 수신자는 ACK 패킷의 헤더의 Window Size를 Zero 로 채워보내서 송신자가 데이터 전송을 멈추게하여 Rx Socket buffer가 넘치는 상황을 방지합니다.
다음 글에서는 혼잡제어에 대해 본격적으로 알아보겠습니다 ~!
* 해당 글은 아래의 내용을 보고 작성하였습니다.
https://blog.naver.com/parkjy76/220885707787
TCP의 흐름제어(Flow Control)와 지연에 따른 스루풋 계산
http://intronetworks.cs.luc.edu/1/html/slidingwindows.html <- 이 사이트는 꼭 읽어보기 6 &nbs...
blog.naver.com
'논문 > QUIC' 카테고리의 다른 글
| [Congestion control] -혼잡제어 알고리즘 (0) | 2023.03.03 |
|---|---|
| [Congestion control] -혼잡제어에 대한 소개 (2) | 2023.02.23 |
| 리눅스 tc 명령어 사용법 (0) | 2023.02.19 |
| QUIC 프로토콜 이해 - 2장. 웹을 파헤치는 이유와 방법 (0) | 2022.12.19 |


