
minzzl
[Congestion control] -혼잡제어 알고리즘 본문
안녕하세요 ~!
지난번까지는 TCP의 신뢰성을 보장하는 제어기법에 대해서 살펴보았습니다.
특히 흐름제어와 혼잡제어에 대해 살펴보았죠.
오늘은 혼잡 제어 알고리즘에 대해 알아볼텐테요, 그 전에 혼잡제어에 대한 내용들을 다시끔 상기시켜보겠습니다.
익히 들어 알겠지만, 혼잡제어란 말 그대로 네트워크의 혼잡 상태를 파악하고 그 상태를 해결하기 위해 데이터 전송을 제어하는 것입니다.
네트워크는 워낙 광대한 블랙박스이기 때문에 정확히 어디서 어떤 이유로 전송이 느려지는지 파악하기 힘들지만, 단순히 느려지고 있다 정도는 각 종단에서도 충분히 파악할 수 있습니다. 그냥 데이터를 보냈는데 상대방으로 응답이 늦게 오거나 안오면 뭔가 문제가 있다는 뜻이니까 말이죠. 또한 흐름제어나 오류 기법들을 사용하다보면 자연스럽게 재전송이라는 작업이 반복될 것입니다. 재전송이 한 두개면 모르겠지만, 네트워크는 워낙 다양한 친구들이 함께 이용하는 공간이다보니 한번 네트워크가 뻑 나기 시작하면 여기저기서 재전송이 일어날 것이고, 이것이 반복되면 점점 악화 될 것입니다.
그래서 이런식으로 네트워크의 혼잡 상태가 감지되면, 이런 최악의 상황을 최대한 회피하기 위해 송신측의 윈도우 크기를 조절하여 데이터의 전송량을 강제적으로 줄이기 되는데 이것이 바로 혼잡제어입니다.
혼잡 윈도우 (Congestion Window, CWND)
송신측의 윈도우 크기는 수신측이 보내준 윈도우 크기(흐름제어와 관련)와 네트워크 상황을 함께 고려해서 정해집니다. 송신측은 자신의 최종 window 크기를 정할 때 수신측이 보내준 윈도우 크기인 수신자 윈도우(RWND), 그리고 자신이 네트워크 상황을 고려해서 정한 윈도우 크기인 혼잡윈도우 중에서 더 작은 값을 사용합니다.
즉 아래에서 설명할 혼잡제어 기법들의 늘었다 줄었다 하는 윈도우는 송신윈도우가 아니라 혼잡윈도우인 것입니다. 그렇다면, 통신 중에는 네트워크의 혼잡도에 따라 혼잡 윈도우의 크기를 유연하게 변경한다고 해도, 통신이 시작하기 전에는 이 혼잡 윈도우의 크기를 어떻게 초기화시키는 것일까요?
혼잡 윈도우 초기화 하기
통신을 하는 중간에는 ACK가 유실된다거나 타임아웃이 난다거나 하는 등의 정보를 사용하여 네트워크의 혼잡 상황을 유추할 수 있지만, 통신을 시작하기 전에는 그런 정보가 하나도 없기 때문에 혼잡 윈도우의 크기를 정하기가 조금 애매합니다. 여기서 등장하는 것이 바로 MSS(Maximum Segment Size)입니다.
MSS는 한 세그먼트에 최대로 보낼 수 있는 데이터의 양을 나타내는 값인데, 대략 계산을 통해 구할 수 있습니다.
MSS = MTU - (IP 헤더길이 + IP 옵션 길이) - (TCP 헤더길이 + TCP 옵션 길이)

여기서 등장하는 MTU(Maximum Transmission Unit)라는 친구는 한번 통신 때 보낼 수 있는 최대 단위를 의미합니다.
즉, MSS는 한번 전송할 때 보낼 수 있는 최대 단위가 정해져있는 상황에서 IP 헤더, TCP 헤더 등 데이터가 아닌 부분을 전부 발라내고 진짜 데이터를 담을 수 있는 공간이 얼마나 남았는지를 나타내는 것입니다. (대체로 MTU는 1500)
혼잡 회피 방법
TCP는 지난 50여년 동안 지속적으로 개선된 다양한 혼잡제어 정책들을 가지고 있습니다.
각 혼잡 제어 정책은 어떤 시점을 혼잡한 상태라고 파악할 것인지, 혼잡 윈도우 크기를 줄이거나 키우는 방법을 개선하여 점점 발전해왔지만 가장 기본적인 혼잡 제어 방법은 Slow start와 AIMD 라는 혼잡 회피 방법을 상황에 맞게 조합하는 것입니다.
1988년 첫 등장한 혼잔 제어 알고리즘 Tahoe 은 후에 등장하는 알고리즘에 많은 영향을 미쳤습니다. 지난 혼잡제어 글에서 단계적으로 윈도우 사이즈를 증가시키고 대역폭을 증가키는 slow start, 재전송 타임 아웃을 기다리지 않고 패킷을 송신하는 Fast recovery 등을 알아보았는데요.. Reno에서는 Tahoe를 개량한 고속 회피 알고리즘을 도입하기도 했습니다.
그 뒤의 수 많은 알고리즘은 통계나 수학적 이론을 채용하여 진화를 거듭해오고 있습니다. 특히 2000년 이후 특정 물리 네트워크와 통신환경에 맞춘 알고리즘이 속속 생겨나고 있습니다. 예를 들어 고정 지연·광대역에서 효율이 높은 BIC, CUBIC, "H-TCP, Fast TCP, Illinois",
저 지연·광대역인 데이터 센터를 위한 최적화된 DCTCP, 모바일 회선 및 Wifi 등 무선 환경에 적합한 Veno 나 Westwood 등이 있습니다. 즏 여러가지 알고리즘을 용도에 맞게 구분할 수 있습니다.
이러한 TCP 혼잡 제어 알고리즘은 크게 3가지로 나뉩니다.
- 패킷 로스를 관측하는 손실 기반 방식
- RTT를 지표로 하는 지연 기반 방식
- 양쪽 방식을 사용하는 하이브리드 방식
손실 기반 방식은 패킷로스를 관측하고 손실이 늘어나면 혼잡이 발생했다고 간주하고 전송량을 억제하는 방법입니다. 대표적인 예로 Reno, NewReno, H-TCP, BIC, CUBIC 등이 있습니다.
지연 기반 방식은 패킷의 RTT를 관측하고 RTT가 늘어나면 혼잡상태가 된 것으로 판단하고 전송량을 줄입니다. 대표적인 예로는 Vegas, Westwood, Fast TCP 등이 있습니다.
하이브리드 방식의 예로는 Illinois, DCTCP 와 함께 CTCP와 YeAH 등이 있습니다.
그렇다면 각각의 혼잡 제어 알고리즘을 알아보기 전, 혼잡 회피 방식인 AIMD와 slow start 에대해서 살펴 보겠습니다.
우리는 혼잡 제어에 대해 배울 때 다음과 같은 그림을 마주한 적이 있습니다.

Slow Start 로 통신을 시작해서 지수승으로 congestion window의 크기를 늘려가다가, 임계점에 도달하면 congestion avoidance 단계로 진입해서 패킷 로스가 일어나기 전까지 congestion window 크기를 1씩 늘려갑니다. 그러다가 혼자 상황 발생 시, 윈도우를 절반 크기로 줄이죠 .
각 단계에서 일어나는 window의 크기 변화와 관련된 혼잡 회피 방식에 대해 알아봅시다.
AIMD (Addictive Increase Multicative Decrease)
우선 AIMD 는 데이터의 전송 속도를 제어하는 방법입니다. Slow Start단계에서, Congestion Avoidance 단계에서, window 크기를 지수승으로 늘리거나 1씩 늘리는 것과 같은 window 크기를 어떻게 늘리고 줄일 것인지에 대한 약속이죠.
우리 말로 번역하면 합 증가 - 곱 감소 알고리즘입니다. 즉, 네트워크에 아직 별 문제가 없어서 전송 속도를 더 빠르게 하고 싶다면 혼잡 윈도우 크기를 1씩 증가시키지만, 중간에 데이터가 유실되거나 응답이 오지 않는 등의 혼잡 상태가 감지되면 혼잡 윈도우 크기를 반으로 줄입니다.
늘어날 때는 ws + 1, 줄어들 때는 ws * 0.5 이므로 말 그대로 합 증가 곱 감소입니다. 이렇게 늘어날 때는 선형적으로 조금씩 늘어나고 줄어들 때는 반으로 확줄어드는 AIMD 방식의 특성상, 이 방식을 사용하는 연결의 혼잡윈도우를 그래프로 그려보면 다음과 같습니다.
송신자는 처음에 하나의 패킷을 전송합니다. 전송된 패킷이 문제 없이 도착하는 것을 확인하면 윈도우 사이즈를 하나 증가시켜 두개를 보냅니다. 이러한 식으로 하나씩 윈도우 사이즈를 늘려나가다 패킷이 전송되지 않거나 TIME_OUT 이 발생하면 늘려놨던 윈도우 사이즈를 절반으로 줄입니다.
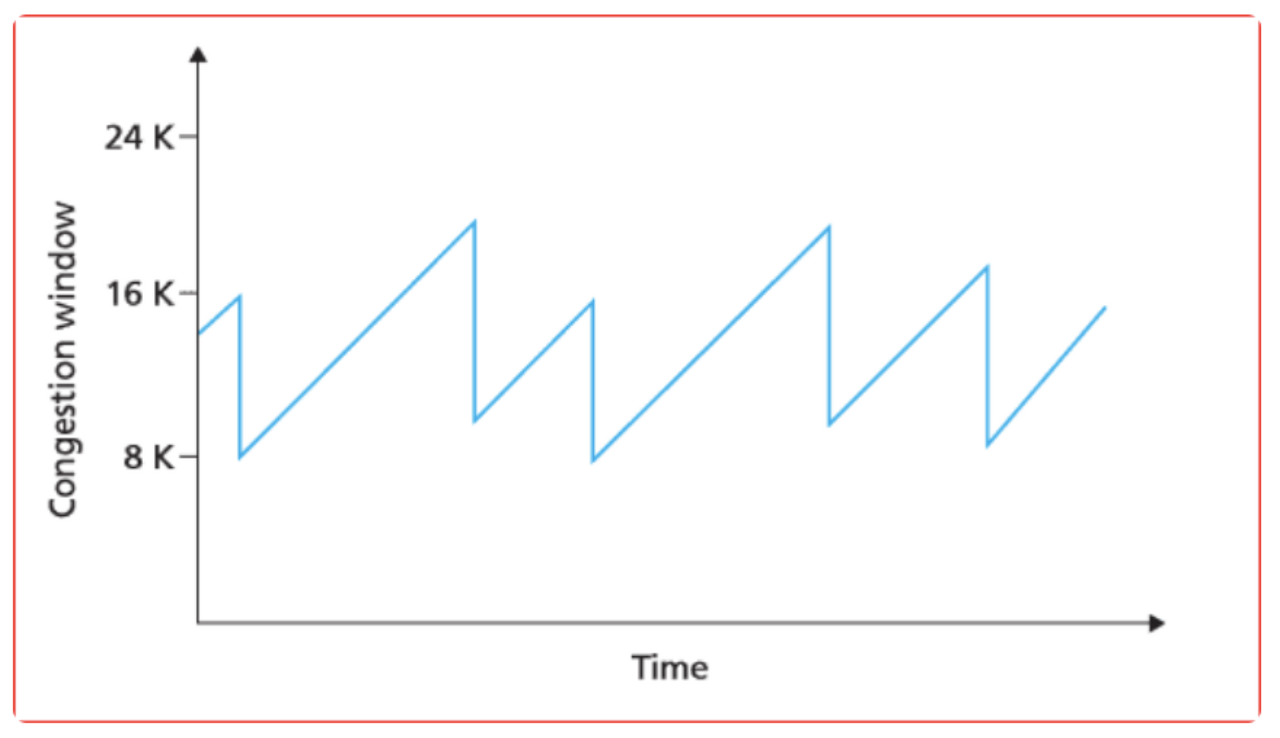
이 단순한 AIMD 알고리즘을 통해서 모든 호스트가 네트워크를 공평하게 사용할 수 있습니다.
네트워크가 혼잡해져있는 상태에서 새로운 호스트가 집입했고 가정해봅시다.
이미 네트워크에 존재하던 호스트들은 큰 혼잡 윈도우를 가지고 있을 것이고, 새로 진입한 호스트의 혼잡 윈도우는 작을 것입니다. 그래서 처음에는 새로 진입한 호스트가 불리합니다. 그러나 네트워크가 혼잡해지면 기존에 존재하던 호스트들은 큰 혼잡 윈도우를 가지고 있으므로 이미 혼잡한 네트워크에 무리하게 많은 데이터를 재전송하여 데이터가 더욱 유실될 것이고 자연스레 혼잡 윈도우 사이즈를 줄이게 됩니다.
이런 상황이라면 네트워크에 일찍 참여해서 이미 혼잡 윈도우 크기가 큰 놈은 자신의 윈도우 크기를 줄여서 혼잡 상황을 해결하려고 할 것입니다. 그러면 새로 들어온 호스트는 자신의 혼잡 윈도우 사이즈를 하나씩 늘려나며 남게되는 대역폭을 사용하게 되고 이러한 과정이 반복되며 여러 호스트들이 대역폭을 공평하게 나눠쓰는 형태로 향합니다.
그런 이유로 시간이 갈 수록 네트워크에 참여한 순서와 관계없이 모든 호스트들의 윈도우 크기가 평행 상태로 수렴하게됩니다.
하지만 단점으로는 윈도우 사이즈를 하나씩 늘려가기 때문에 초기 네트워크의 큰 대역폭을 바로 사용하지 못한다는 점 때문에 네트워크의 모든 대역폭을 활용해 제대로 된 속도로 통신하기 까지 시간이 좀 걸립니다.
또한 네트워크가 혼잡해지는 상황을 미리 감지할 수 없고 혼잡 상태가 발생한 이후에 대역폭을 감소시키기 때문에 비효율적입니다.
윈도우 크기 수렴
사실 AIMD는 워낙 단순한 방식이다보니 간단한 예제를 통해 네트워크의 상황을 재현해볼 수도 있습니다. 이렇게 직접 구현해보면 말로만 들었을 때는 애매한 호스트들의 윈도우 크기가 평행으로 수렴한다는 것이 어떤 의미인지 확인해볼 수 있습니다.
(Evan Moon 님이 실험하신 내용을 바탕으로 확인해보겠습니다.)
우선 실험 환경부터 살펴보겠습니다.
- 네트워크의 혼잡도 최고치는 50이며, 이 혼잡도는 네트워크에 참여한 호스트들이 가진 혼잡 윈도우 크기의 총합으로 결정된다.
- 네트워크에 호스트를 300ms에 하나씩 생성해서 추가한다.
- 각 호스트는 100 ~ 200ms 마다 네트워크의 현재 혼잡도를 계산하고 자신의 윈도우 크기를 조절한다.
- 각 호스트는 윈도우 크기 조절을 300회까지 수행하고 네트워크를 빠져나간다.
하지만 해당 실험에 허점이 있다고 합니다. Evan Moon 님께서는 호스트들의 연산 동시성을 부여하기 위해 setInternal을 사용했는데, setInterver의 콜백도 이벤트 루프를 거친 후 결국 콜 스택에 쌓아가며 수행되기 때문에 실제 네트워크처럼 호스트들의 연산에 완전한 병렬성이 보장되지는 않습니다. 그러나 해당 실험은 늦게 참여한 호스트들도 충분한 혼잡 윈도우 크기를 가질 수 있는지 확인하는 용도이기 때문에 큰 문제가 되지 않기에 그대로 진행하셨다고합니다.

그래프를 살펴보면 네트워크에 일찍 들어온 호스트들과 뒤 늦게 들어온 호스트들의 혼잡 윈도우의 크기는 그렇게 큰 차이가 없습니다. 마지막에 혼자 치솟고 있는 친구는 다른 호스트들이 다 빠져나간 후에 네트워크가 텅텅 비었기 때문입니다.
이런 식으로 시각화해보니 각 호스트들의 혼잡 윈도우 크기가 큰 차이 없이 어느 부분에 수렵하고 있다는 것을 확인할 수 있습니다. 그렇다면 네트워크에 들어와있는 호스트들의 전체윈도우 크기는 시계열 그래프로 시각화해보면 어떨까요?
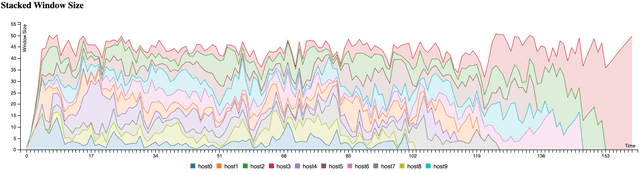
확실하게 네트워크 내 전체 호스트의 혼잡 윈도우 크기를 보니, Evan 님께서 설정하신 네트워크 혼잡도인 50을 넘지않는 선에서 자기들끼리 엎치락 뒤치락 윈도우 크기를 조절하고 있는 모습을 확인할 수 있습니다.
마찬가지로 이 그래프를 확인해보아도 호스트들이 네트워크에 입퇴장하는 초반부와 후반부를 제외하면 중간 즈음에서는 각 호스튿들의 혼잡 윈도우 크기가 크게 차이가 나지 않습니다.
그다음으로 Slow start 방식도 알아보겠습니다.
Slow Start
위에서 이야기 한것처럼 AIMD(Addictive Increase Multicative Decrease) 방식은 윈도우가 선형적으로 증가하기 때문에 제대로된 속도가 나오기전까지는 시간이 조금 걸립니다.
요즘에는 네트워크의 대역폭이 워낙 넓고 통신 인프라도 좋다보니 예전에 비해서 네트워크의 혼잡상황이 발생하는 빈도가 많이 줄어들었습니다. 때문에 혼잡 상황이 발생하기 전에도 제대로 속도를 내지 못하는 AIMD 의 단점이 부각되었다고 합니다.

Slow start 방식도 동일하게 처음에 패킷을 하나씩 전송합니다. 패킷이 문제 없이 도착하면 각각의 ACK 패킷 마다 window를 두배씩 증가시킵니다. 윈도우 사이즈를 빠르게 두배씩 증가시키다가 혼잡 현상이 발생시 윈도우 사이즈를 1로 확 줄여버립니다.
Slow Start 방식은 윈도우 사이즈를 1개씩 늘려가던 AIMD 방식과 다르게 지수적으로 윈도우 사이즈를 증가시켜 빠르게 네트워크의 대역폭을 사용합니다.
기본적으로 AIMD와 어떤 방식으로 윈도우 크기를 증가시키냐, 감소시키냐의 차이만 존재하기 때문에 위에서 작성한 예시에서 윈도우 사이즈를 변경하는 부분만 변경하면 다음과 같은 Slow Start 차트를 그릴 수 있습니다.

그림을 보면 네트워크 혼잡도의 최고치인 50보다 호스트들의 혼잡윈도우가 커지는 경우가 발생합니다. 이건 자바스크립트가 setInternal의 call back 을 처리하는 과정에서 발생한 문제이므로 실제 네트워크에서는 이러지 않습니다.
AIMD와 Slow start의 가장 큰 차이점은 네트워크 혼잡도의 최고치에 도달하는 시간입니다.
AIMD는 윈도우 크기를 선형적으로 증가시키기 때문에 다른 호스트들이 새로 들어올 때 많은 부분을 점유할 수 없지만, Slow start 방식을 사용하면 처음에는 윈도우 크기를 느리게 키우다가 아직 여유가 있다고 판단되면 지수적으로 증가시킬 수 있으므로 결과적으로 AIMD 보다 윈도우 크기를 더 빠르게 키울 수 있습니다.
이러한 TCP 회피 방식들을 활용한 다양한 혼잡 제어 정책이 존재하고, 정책들은 AIMD, Slow Start를 적절히 섞어서 사용하되 네트워크 혼잡 상황이 발생했을 때 어떻게 대처하는지에 따라서 나뉘게됩니다.
또한 정책들은 혼잡이 발생하면 윈도우 크기를 줄이거나 혹은 증가시키지 않으며 혼잡을 회피한다는 공통점을 가지고 있습니다.
먼저 패킷 로스를 관측하고, 손실이 늘어나면 혼잡이 발생했다고 간주하고, 전송량을 억제하는 손실기반 방식부터 살펴보겠습니다.
Tahoe (타호)
Tahoe 정책은 혼잡 제어의 초기 정책이고 빠른 재전송이 처음으로 도입된 정책입니다. Tahoe 이후의 혼잡 제어 정책은 Tahoe와 마찬가지로 빠른 재전송 기법을 기본으로 사용하되, 효율을 위해 몇가지를 더 도입합니다.
3개의 연속된 DUP_ACK를 받는 경우는 수신자가 packet loss 이후 다른 3개의 packet을 수신해서 보낸 것이라고 판단하고 바로 retransmission을 수행하도록 했습니다.(Fast Retransmission)

처음에는 동일하게 Slow Start 방식으로 윈도우를 증가시키다가 ssthresh 시점 이후부터는 AIMD 방식을 사용합니다. 이후 TimeOut 이나 3 ACK Duplicated 상황이 발생 시 네트워크가 혼잡하다는 것을 인지하고 ssthresh 는 혼잡 상황 발생 시 ssthresh를 절반으로, 윈도우 사이즈는 1로 수정하는 방식입니다.
이 방법에서는 혼잡 상황이 발생할 때마다 윈도우를 1로 초기화해 다시 증가시켜 나가는 부분이 비효율적이기 때문에 빠른 회복을 적용한 TCP Reno 정책이 있습니다.
Reno

TCP Tahoe 정책과 동일하지만 3 ACK Duplicated와 Time Out을 구분해서 대응한다는 차이점이 있습니다.
3 ACK Duplicated 이 발생하면 윈도우 크기를 1로 초기화 하지 않고 AIMD 처럼 윈도우 크기를 절반으로 줄이며 ssthresh 값 역시 줄어든 윈도우 값으로 설정합니다.
이러한 방식으로 빠르게 윈도우 사이즈를 회복시켜 네트워크 대역폭을 사용하도록, 이를 빠른 회복이라고 합니다.
TimeOut 이 발생한다면 TCP Tahoe와 동일하게 윈도우 사이즈를 1로 줄이고 Slow Start를 시작하지만 ssthresh 값은 변경하지 않습니다.
Tahoe와 Reno 같은 경우에는 예전의 네트워크 환경을 고려하며 설계되었기 때문에 최근의 빵빵한 네트워크에는 다소 맞지 않습니다.

Tahoe나 Reno가 개발된 시절의 네트워크 대역폭과 비교하면 훨씬 더 여유있기 때문에 송신측이 혼잡 윈도우의 크기를 마음 놓고 팍팍 늘려도 문제가 발생할 확률이 예전보다 많이 낮아졌습니다. 그렇기 때문에 최근의 혼잡 제어 정책들은 얼마나 더 빠르게 혼잡 윈도우 크기를 키우고 어떻게 혼잡 감지를 더 똑똑하게 할 것이냐에 대해 초점이 맞춰져있습니다.
Tahoe와 Reno에 대해 먼저 알아본 이유는, TCP 사용 초반에 개발되어 원리가 간단하고 이후 개발된 방식들도 큰 틀을 해당 알고리즘에서 크게 벗어나지 않았기 때문입니다.
BIC
BIC(Binary Increase Congestion Control)는 slow start, congestion avoidance, fast retransmission/fast recovery 와 같은 전통적인 TCP 혼잡 제어 알고리즘의 일부 제한을 해결하도록 설계되었습니다.
BIC는 이진 검색 원리를 기반으로 congestion window 크기를 결정하는 이진 검색 알고리즘입니다. 이진 검색 접근법을 사용하여 패킷 손실을 감지할 때까지 congestion window 를 증가시키고, 패킷 손실 발생 시, 시점에서 정체 창을 반으로 나누고 새로운 이진 검색을 시작합니다. 이를 통해 BIC는 네트워크 정체에 신속하게 적응하고 패킷 손실에서 복구하는 데 걸리는 시간을 줄일 수 있습니다.
BIC(Binary Increase Congestion Control) 알고리즘은 이진 검색(binary search) 접근법을 사용하여 네트워크 정체에 대응하여 적절한 congestion window 크기를 결정합니다.
BIC에서 사용하는 이진 검색 알고리즘은 기본 값으로 설정된 초기 congestion window 크기로 시작합니다. 그런 다음 송신자는 패킷 손실이 발생할 때까지 congestion window 크기를 점진적으로 증가시켜 네트워크가 정체되었음을 나타냅니다.
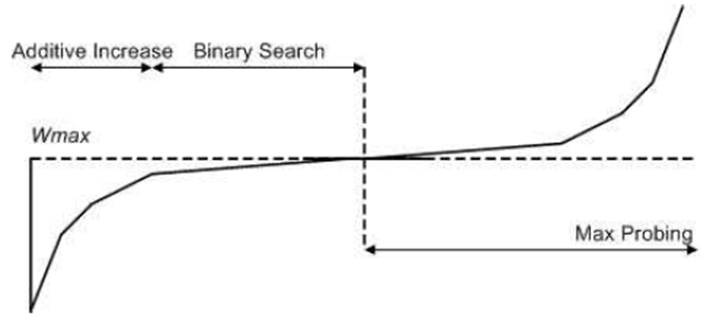
이때 sender는 congestion window 크기를 현재 크기와 초기 크기 사이의 중간 지점으로 줄여 이진 검색을 수행합니다.
예를 들어, 초기 정체 창 크기를 10 패킷으로 설정하고 정체 창 크기가 50 패킷에 도달할 때 패킷 손실이 발생한다고 가정합니다. 이 경우, sender는 혼잡 창 크기를 30 패킷(즉, 10과 50 사이의 중간점)으로 줄일 것입니다. 그런 다음, 송신자는 패킷 손실이 다시 발생할 때까지 혼잡 창 크기를 계속 증가시키며, 혼잡 창 크기를 현재 크기와 이전 중간 지점 사이의 중간 지점으로 줄임으로써 이진 검색 프로세스를 반복합니다.
즉, BIC에서는 packet 손실이 일어나기전까지 점진적으로 congetion window 크기를 늘려나가다가(slow start), packet 손실 발생시 binary search 접근법을 사용하여 congestion window 크기를 줄입니다. 그러나 이렇게 했을 때, congestion window의 크기가 너무 줄어들면 복구 프로세스가 너무 느려져 처리량이 감소하고 전송시간이 길어질 수 있습니다.
이 문제를 해결하게 위해 BIC 에는 Max probing 이라는 기능이 포함되어 있습니다. 다시 말해 Max probing은 BIC 알고리즘의 기능입니다. TCP 송신자가 과도한 패킷손실을 방지하면서 네트워크에서 사용가능한 대역폭을 신속하게 검색할 수 있도록 설계되었습니다. Max probing를 사용하면, 패킷 손실이 일어났더라도, TCP sender가 일시적으로 congestion window 크기를 2배로 증가시킬 수 있습니다.
예를 들어, congestion window 크기가 현재 100패킷이고 패킷 손실이 발생한다고 가정해봅시다.
이 경우, 이진 검색 접근법을 사용하면 혼잡 창크기가 50으로 줄어들 것입니다. 그러나 Max probing을 사용하면 혼잡 창 크기가 일시적으로 200 패킷으로 증가하여 TCP 송신자가 이진 검색 프로세스로 돌아가기전에 사용가능한 대역폭을 빠르게 검색할 수 있습니다.
Max probing은 혼잡제어 알고리즘의 복구 시간을 향상시켜 TCP 송신자가 패킷 손실에서 신속하게 복구하고 이전 처리량 수준을 되찾을 수 있도록 합니다. 그러나 Max probing 을 신중하게 사용하여 과도한 패킷 손실 또는 네트워크 정체를 방지하는 것이 중요합니다.
물론 아시겠지만, Max Probing은 계속해서 사용하는 것이 아닙니다. congestion window의 크기가 일정 수준 아래로 내려갔을 때 활성화됩니다. 이 임계값은 일반적으로 congestion window 크기의 백분율로 설정됩니다. 예를 들어 최대 congestion window의 크기가 10000 패킷인 경우 최대 임계값을 이 값의 10% 또는 1000 패킷으로 설정할 수 있습니다.
congestion window의 크기가 앞서 말한 임계 값 아래로 떨어지면, congestion window 는 일시적으로 패킷 손실 지점의 congestion window에서 2배를 증가시킵니다. 이를 통해 TCP sender는 네트워크에서 사용 가능한 대역폭을 빠르게 검색하고 패킷 손실에서 더 빨리 복구 할 수 있습니다. 그러나 이렇게 증가된 congesrion window 크기는 일시적이며, max probing 단계가 완료되면 이진 검색 접근법을 사용하는 것으로 되돌아갑니다. 이 때 TCP sender가 네트워크 상태를 모니터링 하여 Max probing을 계속해서 사용할지, 이진 검색 방식으로 돌아갈지 결정합니다. 네트워크 조건이 개선되고, max probing 단계 동안 패킷 손실이 발생하지 않으면 TCP sender는 이진 검색 접근법을 사용합니다.
그렇다면 TCP sender는 어떻게 네트워크 상황을 모니터링하는 걸까요?
네트워크의 동작과 전송된 패킷의 수신자를 관찰하여 네트워크 상태를 모니터링 합니다.
수신자가 네트워크 상태를 모니터링 할 수 있는 방법은 다음과 같습니다.
- RTT 측정 : TCP sender는 패킷이 sender 에서 reciever 로 이동하고 다시 돌아오는데 걸리는 시간을 측정합니다. RTT는 네트워크지연 및 혼잡 수준을 추론하는데 사용될 수 있습니다.
- Congestion window size : TCP sender는 congestion window 크기를 모니터링 하며, 이는 승인 대기 전에 전송할 수 있는 패킷수를 나타냅니다. congestion window의 크기가 작으면 네트워크가 혼잡할 수 있음을 나타냅니다.
- Packet loss : TCP sender 는 reciever window 크기를 모니터링하며, 이는 reciever window 크기가 작으면 reciever 가 혼잡하거나 데이터 처리 속도가 느릴 수 있음을 나타냅니다.
이러한 관찰에 따라 TCP sender는 max probing을 계속할지 아니면 이진 검색방식으로 돌아갈지 결정할 수 있습니다. 네트워크 조건이 양호하고 패킷 손실이 발생하지 않는 경우, TCP sender는 바이너리 접근법을 사용하여 정체창 크기를 점진적으로 증가시킵니다. 그러나 Max probing 중 패킷 손실이 발생하면 congestion window 크기가 줄어들며 TCP 송신자는 추가로 사용가능한 대역폭을 사용할 수 있는지 여부를 확인하기 위해 다른 Max probinf 검색단계를 수행 할 수 있습니다.
전반적으로 max probing은 패킷 손실이 발생 할 때 혼잡 제어 알고리즘의 복구 시간을 향상 시키는데 도움이 될 수 있습니다.

* Addictive Increase
TCP BIC에서 Addictive Increase는 패킷 손실 이벤트에 의해 트리거된 곱셈 감소 단계 이후에 발생하는 단계입니다. Additional Increase 동안, congestion 이벤트의 발생 여부에 관계없이, congestion 윈도우 크기는 성공적인 전송의 라운드 트립 시간(RTT)마다 고정된 양만큼 증가한다. 이는 slow start 동안 혼잡 창이 기하급수적으로 증가하고 혼잡 회피 동안 곱셈이 감소하는 것과 대조적입니다.
TCP BIC에서 패킷 손실이 감지되면 Additive Increase 단계로 전환됩니다. 패킷 손실이 관찰되면 TCP BIC는 congestion window 크기를 절반으로 줄이고 Additive Increase 단계로 들어갑니다. 이 단계에서 혼잡 윈도우는 혼잡 윈도우 임계값에 도달할 때까지 일정한 가산 계수와 선형적으로 증가합니다. 임계값은 현재 네트워크 조건을 기준으로 계산되며 일반적으로 관찰된 최대 정체 창 크기보다 약간 낮게 설정됩니다. 임계값에 도달하면 TCP BIC가 다시 이진 증가 단계로 들어가 최적의 정체 창 크기를 결정하기 위해 이진 검색을 수행합니다.
Additional Increase(추가 증가) 동안의 증가량은 패킷 손실 이벤트 발생 시의 혼잡 창 크기에 따라 결정됩니다. BIC에서 증가는 가법적이며, 이는 혼잡 창 크기가 각 RTT에 대해 고정된 양(일반적으로 하나의 MSS - 최대 세그먼트 크기)만큼 증가함을 의미합니다. 이로 인해 느린 시작의 기하급수적인 증가에 비해 정체 창 크기가 느리지만 더 안정적으로 증가합니다.
Additional Increase의 목표는 혼잡 이벤트 후에 혼잡 창 크기를 점진적으로 증가시켜 사용 가능한 네트워크 대역폭을 더 잘 활용하는 동시에 다른 혼잡 이벤트를 트리거하지 않도록 하는 것입니다.
그러나 BIC에도 단점이 존재했습니다.
BIC은 고속 네트워크에서 효율적이고 효과적인 혼잡제어를 제공하도록 설계되었지만, 특정 상황에서 성능에 약간의 문제가 있었습니다. 다음은 CUBIC 개발을 이끈 몇가지 문제점들입니다.
- Slow Convergence : BIC은 패킷 손실이 발생 할 때까지 혼잡 창 크기를 점진적으로 증가시킴으로써 고속 네트워크에서 효육적이고 효과적인 제어를 제공하도록 설계되었습니다. 그러나 이 접근 방식은 혼잡 기간동안, 특히 BDP(Bandwidth delay product)가 높은 네트워크에서, slow convergence 를 초래할 수 있습니다. BDP는 송신자와 수신자 사이에서 전송될 수 있는 데이터의 양을 측정하는 것으로 네트워크의 대역폭과 왕복시간의 곱에 정비례합니다. 이 때 slow convergence란 TCP congestion control 알고리즘에서 혼잡에 대해 응답하는 시간이 오래걸리는 것을 의미합니다. 따라서 네트워크의 상황에 신속하게 대응할 수 없기 때문에, 네트워크의 변환에 적응하는데 오랜시간이 걸리고 지연시간 증가 및 패킷손실을 초래합니다. 추가적으로 네트워크가 신속하게 대응할 수 없기 때문에 네트워크가 더 이상 활성화 되지 않는 연결을 하거나 등의 리소스 낭비를 초래합니다.
- Suboptimal Throughput : 특히 BDP가 높은 네트워크에서 BIC은 혼잡 기간동안 suboptimal throughput을 초래할 수 있습니다. 이는 BIC이 이진 검색방식을 사용하여 혼잡이 감지될 때 혼잡 창 크기를 줄여 congestion window 의 크기와 처리량의 톱니 패턴을 초래할 수 있기 때문입니다. 구체적으로, 패킷 손실이 발생할 때, BIC는 이진 검색 접근법을 사용하여 마지막으로 알려진 혼잡 창 크기와 현재 혼잡 창 크기 사이의 중간 지점을 찾아 혼잡 창 크기를 줄입니다. 즉, BIC는 혼잡 창 크기를 상당히 줄여 처리량이 갑자기 감소할 수 있음을 의미합니다. 혼잡 창 크기가 줄어든 후, BIC는 다른 패킷 손실이 발생할 때까지 혼잡 창 크기를 점진적으로 다시 증가시킵니다. 이러한 정체 창 크기의 점진적인 증가는 정체 창 크기와 처리량의 톱니 패턴을 초래합니다. 이러한 톱니패턴은 네트워크가 최대 용량으로 작동하지 않음을 의미하는 suboptimal throughput 입니다. 이렇듯 네트워크가 최대 용량으로 작동하지 못한다는 것은 데이터를 신속하고 효율적으로 전달 할 수 없음을 의미합니다. 이로 인해 속도가 느려지고 대기시간이 길어지며 사용자 환경에 영향을 줄 수 있습니다. 추가적으로 네트워크가 최대 용량으로 동작하지 않았다는 것은 사용되지 않는 대역폭이 있을 수 있다는 것이므로, 네트워크의 성능과 효율성을 향상 시키는데 사용될 수 있는 낭비된 리소스를 나타냅니다.
- Limited Scalability :BIC은 고속 네트워크에서 효율적이고 효과적인 혼잡제어를 제공하도록 설계되었지만, 10Gbps 이상의 대역폭을 가진 네트워크와 같은 초고속 네트워크에서는 효과적으로 작동하지 않습니다.
이러한 문제를 해결하기 위해 CUBIC은 큐빅 함수를 기반으로한 수학적 모델을 사용하여 congestion window 크기의 증가를 결정하며, 이는 혼잡이 적은 기간 동안 더 공격적으로 congestion window 크기를 빠르게 증가시킵니다. CUBIC은 또한 Fast convergence 라는 매커니즘을 사용하여 혼잡에 대응하여 혼잡 창 크기를 빠르게 줄여 처리량을 향상시키고 congestion window 크기와 처리량의 톱니 패턴을 줄이는데 도움을 줍니다. 또한 CUBIC은 시간 기반 지연 방식을 사용하여 congestion window 크기를 계산하여 혼잡 기간 동안 확장성을 향상시키고 slow convergence를 줄이는데 도움을 줍니다.
CUBIC
이번에는 CUBIC에 대해 알아보겠습니다.
CUBIC(Cubic congestion control)은 BIC(Binary Increase congestion control) 알고리즘의 대안으로 2006년에 도입된 혼잡제어 알고리즘 입니다
CUBIC의 주요 특징 중 하나는 CUBIC fuction(y = x^3 함수)을 사용하여 시간 경과에 따른 혼잡 창 크기를 조정하는 것입니다.


이 함수는 네트워크에서 TCP 흐름의 동작을 근사화하는 수학적 모델을 기반으로 합니다. CUBIC 기능은 전송 속도를 부드럽고 점진적으로 증가시켜 네트워크 트래픽의 갑작스러운 급증을 방지하고 혼잡을 줄일 수 있습니다.
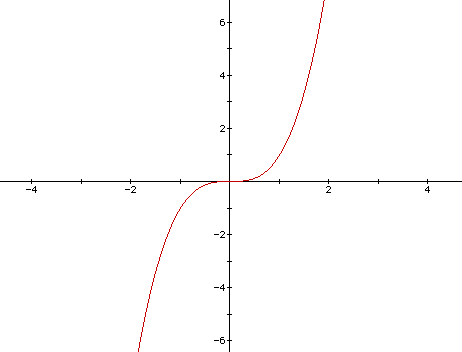
CUBIC에서는 TCP Reno 나 TCP Vegas 와 같은 다른 혼잡제어 알고리즘처럼 명시적인 slow start 단계는 없습니다. 대신 CUBIC은 특정 임계값에 도달할 때 까지 congestion window 크기를 천천히 증가시키는 시작 단계는 사용합니다.
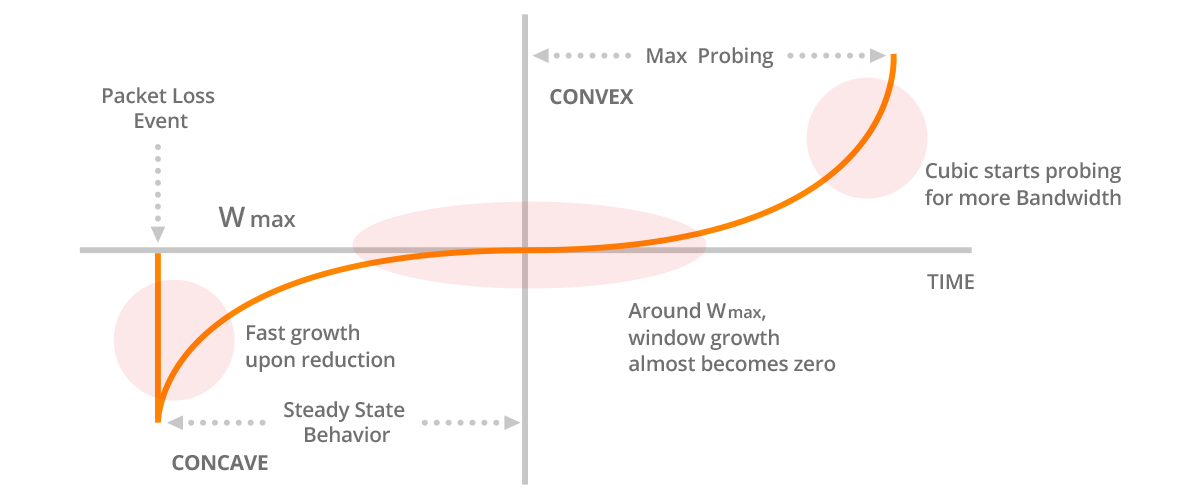
시작단계에서 CUBIC은 congestion window 를 최대 창 크기의 절반으로 설정하고 선형으로 늘립니다. congestion window가 특정 임계값이 도달하면 cubic 증가 기능으로 전환하여 cubic 증가 기능을 사용하여 congestion window 크기를 더욱 증가시킵니다.
시작 단게에서는 cubic이 congestion이 유발하는 것을 방지하고 congestion window 크기가 너무 큰 상태에서 시작되지 않도록 하기 위해 설계되었습니다. 시작 단계가 완료되면 CUBIC은 CUBIC 증가 기능을 사용하여 네트워크 조건에 따라 congestion window 크기를 조정합니다.
또한 이진 검색 메커니즘을 사용하여 패킷 손실을 기반으로 혼잡 창 크기를 조정합니다. 패킷 손실이 감지되면 CUBIC 은 TCP Reno 및 TCP NewReno 와 같은 손실 기반 알고르즘과 유사한 이진 검색 접근법을 사용하여 혼잡 창 크기를 줄입니다. 그러나 CUBIC은 이진 검색 알고리즘을 수정하여 큐빅 기능을 통합하여 혼잡이 감지 되지 않을 때 전송 속도를 보다 점진적으로 증가시킬 수 있습니다.
큐빅의 또 다른 중요한 특징은 congestion window exponent(beta) 를 사용하여 congestion window 곡선 모양을 조정한다는 것입니다. beta 값은 네트워크 조건의 변화에 따라 혼잡 창 크기가 얼마나 공격적으로 증가하거나 검소하는지 결정합니다. 베타 값이 클수록 전송속도가 더 공격적으로 증가하고 베타 값이 낮을 수록 점진적으로 증가합니다.

그러나 이렇듯 뛰어난 CUBIC 이라고 할지라도, 사용가능한 네트워크 대역폭과 서로 다른 네트워크 조건에서 사용할 최적의 congestion window 크기를 정확하게 감지하는 것은 어렵습니다. CUBIC 및 BIC과 같은 전통적인 알고리즘은 혼잡의 표시로 packet 손실을 감지하는데 의존하지만, 이 접근 방식은 높은 수준의 큐잉 및 대기 시간을 가진 네트워크에서는 문제가 될 수 있습니다. (패킷 손실이 queue 버퍼가 꽉 차서 생기는거니까 ..)
BBR (Bottleneck Bandwidth and RTT)
네트워크 혼잡이 발생하는 경우는 2가지가 있다고 말씀드렸습니다. 그 중 하나가 다음과 같은 상황입니다.

두 노드가 1GB 링크를 통해 데이터를 전송하는데, 두 노드가 링크의 용량을 최대한으로 활용해서 데이터를 전송할 경우 중간 지점에서 데이터의 손실이 발생합니다. TCP의 경우 전송하는 노드가 데이터의 손실을 감지하면 해당 데이터를 재전송하기 때문에 위와 같은 경우, 두 노드는 영원히 데이터를 전송하는 지옥에 빠지게 됩니다.
때문에 위와 같은 문제를 해결하기 위해서는 두 노드가 모두 데이터를 보내는 양을 조절해야합니다. 그러나 네트워크 상에서는 각 노드에게 얼마만큼의 데이터를 전송하라고 지시하는 중앙 노드가 없습니다. 그래서 해당 문제를 해결하는 것은 쉽지 않습니다. 또한 자신이 사용하는 링크들의 용량도 알 수 없습니다. 또 어떤 서버로 접근하고자할 때 하나의 링크만을 통과하는 것이 아니라 수십번 혹은 몇 백번까지 링크를 갈아탈 수 있습니다. 그렇게 때문에 내가 한번에 보낼 수 있는 데이터의 양을 매번 체크하는 기능이 필요합니다. 이를 위해 혼잡제어가 존재합니다. Congestion window를 이용해서 congestion 이 발생하지 않도록 적당한 사이즈를 찾기 위해 다양한 매커니즘이 존재합니다. 즉 Congestion window를 통해, 네트워크에 병목 링크 대역폭의 사용을 극대화하여 최대 전송 속도를 결정해야합니다.
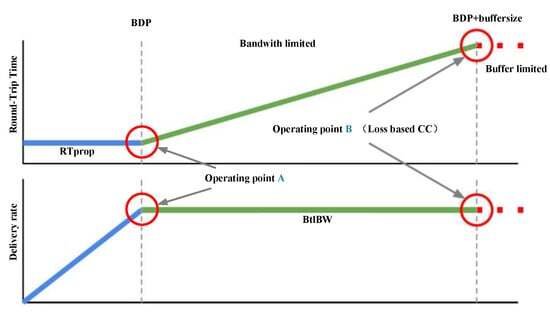
앞서 보았던 손실 기반한 알고리즘은 CWND를 점진적으로 증가시키다 패킷 손실이 감지되면 CWND를 빠르게 감소시킵니다. 그렇기 때문에 버퍼가 오버플로우되었기 때문에 많은 수의 패킷 손실이 발생하며, 그림에서 패킷 손실이 발생하는 지점이 바로 B 지점입니다. 이 방법은 최대 대역폭을 보장할 수 있지만 최소 전송 지연은 보장하지 않습니다.
BBR의 네트워크 병목 대역폭과 RTT를 측정하는데 중점을 주어 다른 접근 방식을 취합니다. 이 정보를 사용하여 TCP 흐름의 전송 속도를 동적으로 조정하여 과도한 큐잉 및 지연을 유발하지 않고 사용 가능한 대역폭을 최대한 활용합니다. 최대 전송률과 최소 RTT를 번갈아 측정하여 최적의 동작 지점을 찾을 수 있도록 합니다. BBR 알고리즘에서 TCP 링크는 파이프로 간주할 수 있습니다.
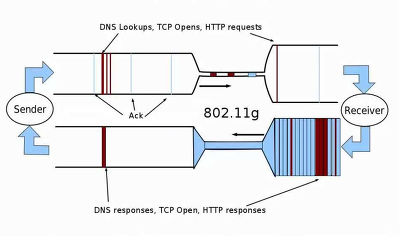
이 파이프의 지름은 BtlBw(가장 느린 링크의 대역폭.), 파이프의 길이는 RTptrop( 대기열 지연이 없고 수신기에서 처리 지연이 없는 경우 왕복 전파에 걸리는 최소 시간), 파이프의 부피는 BDP( 네트워크에서 전송 중인 데이터의 최대 가능한 양으로, 병목 대역폭과 왕복 전파 시간을 곱하여 구할 수 있음) 입니다.
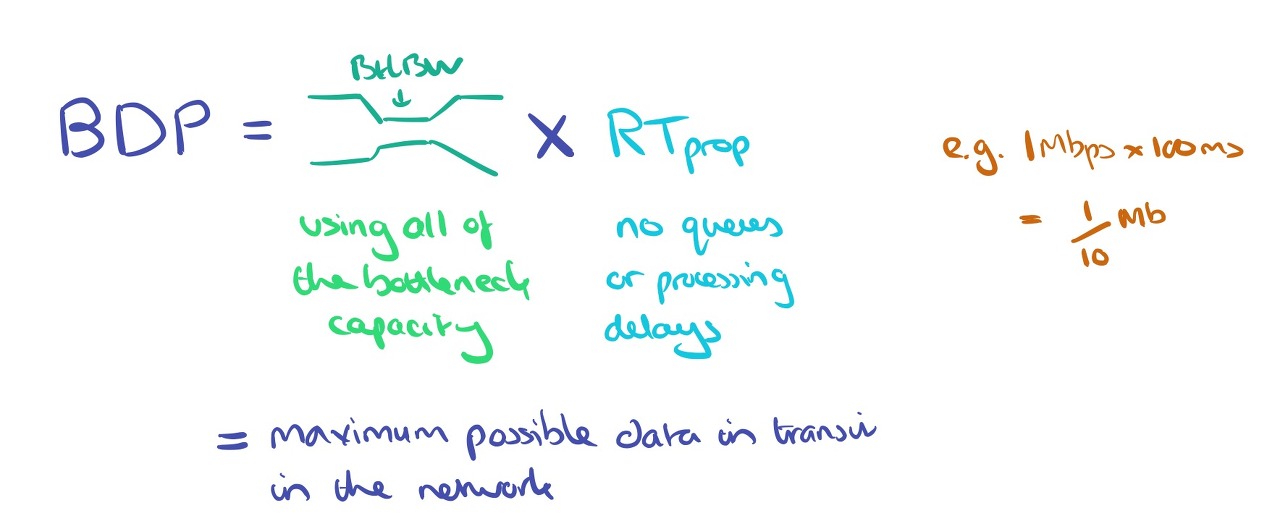
BDP는 네트워크 성능을 이해하는 데 핵심적인 요소입니다. 기내 데이터 전송량을 점차 늘릴 때 전송률은 어떻게 되는지 생각해 보세요. 기내 데이터의 양이 BDP보다 적을 때는 더 많은 데이터를 전송할수록 전송률이 증가하지만, 애플리케이션에 따라 전송률이 제한됩니다. 하지만 병목 지점의 대역폭이 포화 상태가 되면 전송 속도가 더 이상 올라갈 수 없기 때문에 해당 파이프를 통해 데이터를 최대한 빠르게 전송합니다. 버퍼가 가득 차면 결국 패킷이 떨어지기 시작하지만 전송 속도는 여전히 증가하지 않습니다.

파이프의 데이터 양이 BDP이면 전송창이 BDP와 같다는 것이므로 처리량이 최대에 도달할 수 있습니다.

최적의 작동 지점은 BDP 임계값(위의 파란색 점)에 있지만 손실 기반 혼잡 제어는 BDP + 병목 버퍼 크기 지점(위의 녹색 점)에서 작동합니다.
이제 데이터 전송량이 증가하면 RTT에 어떤 일이 발생하는지 살펴보겠습니다. RTT는 RTprop보다 나을 수 없으므로, BDP에 도달할 때까지는 RTT ~= RTprop입니다. BDP를 넘어 버퍼가 채워지기 시작하면 버퍼가 완전히 꽉 차서 패킷을 떨어뜨리기 시작할 때까지 RTT가 올라갑니다.
BBR은 병목 대역폭(Bottleneck bandwidth)과 왕복 전파시간(propagation delay)를 기반으로 하는 혼잡제어 알고리즘입니다. 이 값을 지속적으로 추정하여 패킷손실이나 일시적인 대기열 지연이 아닌 실제 혼잡에 반응하는 혼잡제어 알고리즘입니다.
RTT는 RTpop 보다 작을 수 없기 때문에 최소 RTT를 추적하면 편향되지 않은 효율적인 왕복 전파시간을 얻을 수 있습니다. 기존 TCP ack 는 RTT를 계산하기에 충분한 정보를 제공합니다. RTT와 달리 TCP 사양에는 병목 대역폭을 추적하기 위해서는 bandwidth을 추적하면 됩니다.
앞서 이야기한 BDP와 관련된 이야기인데요, 전송 응답 사이의 평균 bandwidth는 단순히 전송된 데이터 양을 소요 시간으로 나눈 값입니다. 이 수치는 실제 병목 구간 전송률보다 낮아야하기 때문에 전송률 중 가장 높은 전송률을 대역폭 병목 구간의 값으로 사용하면 됩니다.
해당 내용을 다음과 같이 protocol 스택에 구현되어 있습니다.

해당 값들을 이용해서 데이터양을 조절합니다.

BBR은 최근 10회 왕복의 최대 대역폭을 현재 BtlBw로 설정하고, 과거 10초 동안의 최소 RTT 측정값을 감지하여 현재 RTprop를 얻습니다. BBR은 페이싱 속도(pacing rate: 패킷이 네트워크 링크로 전송되는 속도)와 CWND로 전송동작을 제어합니다. 이 때 페이싱은 패킷이 전송되는 속도를 조절하여 혼잡을 방지하고 네트워크 처리량을 최적화하는데 사용되는 기술입니다. CWND는 데이터 양을 제한하기 위해 BDP의 작은 배수로 설정합니다.
현재 전송중인 데이터가 BDP보다 작으면 변목 링크가 대기열에 포함되지 않고 버퍼를 차지하기 않기 때문에 RTT는 고정된 값이 되며, 전송 속도가 증가함에 따라 처리량이 증가합니다. BDP를 초과하면 버퍼가 점유되기 시작하고 전송속도에 따라 RTT는 증가하지만 최대 값(2BDP)에 도달한 후에는 처리량이 증가하지않습니다. 버퍼가 가득차면 초과 데이터 패킷을 버려집니다. BDP는 아래의 그림(위에서 다시 가져옴)의 A인, BDP 지점 근처에서 전송 속도를 유지하므로 더 높은 처리량과 낮은 전송 지연을 보장할 수 있습니다.
BBR은 네트워크 조건의 변환에 신속하게 적응하고 보다 세분화되고 정확한 방식으로 혼잡에 대응하는 보다 신속한 방식으로 작동하는 능력입니다. 이를 통해 BBR은 특히 장거리 및 고속 네트워크의 경우 많은 시나리오에서 CUBIC과 BIC과 같은 기존 알고리즘보다 높은 처리량과 낮은 대기 시간을 달성할 수 있습니다.
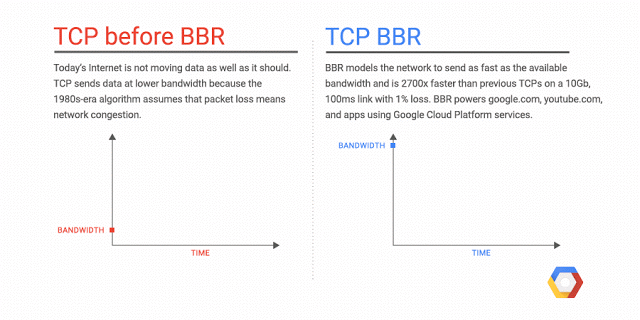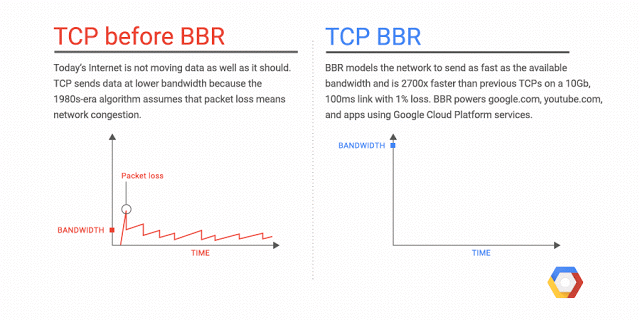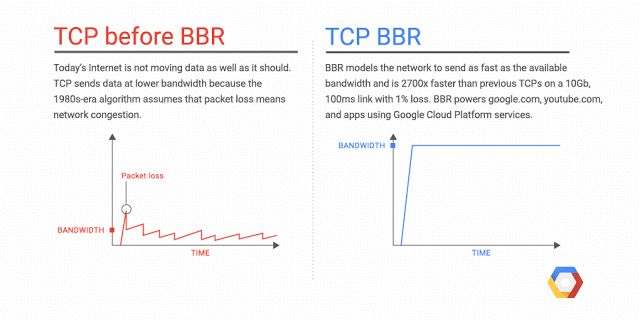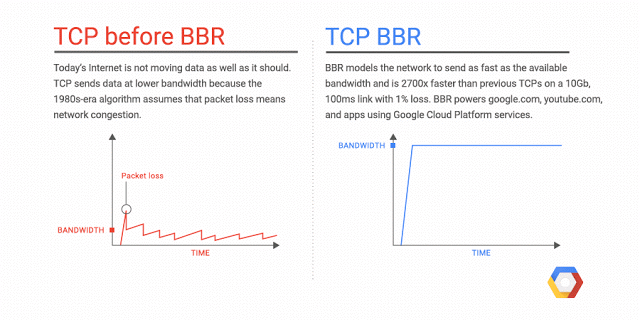
BBR은 네트워크 경로에 대한 정보를 사용하여 혼잡제어 결정을 내리는 모델 기반 알고리즘입니다.
BBR의 주요 기능은 네트워크 경로의 사용 가능한 병목 대역폭과 RTT를 추정하는 기능입니다. 이 정보는 TCP 연결의 전송 속도를 실시간으로 조정하는데 사용됩니다. BBR은 피드백 제어 루프(feedback control loop)를 사용하여 사용 가능한 병목 대역폭에 근접한 안정적인 전송속도를 유지합니다.
BBR... 그거 어캐하는건데 ...
BBR에서는 패킷이 네트워크로 전송되는 속도를 제어하기 위해 pacing_gain 매개변수를 사용합니다. 페이싱의 목표는 너무 많은 패킷으로 네트워크에 무리를 주지 않으면서 네트워크의 가용 대역폭에 맞게 전송 속도를 조절하는 것입니다. BBR은 최적의 성능을 달성하기 위해 추정된 RTprop 및 BtlBw를 기반으로 pacing_gain을 조정합니다.
BBR은 최대 지속 전송 속도가 네트워크의 사용 가능한 병목 대역폭에 의해 제한된다는 관찰을 기반으로 하는 BtlBw 추정 알고리즘을 사용하여 네트워크의 사용 가능한 대역폭을 추정합니다. 또한 BBR은 주어진 시간에 전송할 수 있는 데이터의 양을 제어하는 데 사용되는 네트워크의 왕복 전파 지연(RTprop)을 추정합니다.
이러한 추정치를 기반으로 BBR은 최적의 성능을 달성하기 위해 pacing_gain 파라미터를 조정합니다. BBR이 시작 단계에 있을 때는 전송 속도를 빠르게 높이고 네트워크 버퍼를 채우기 위해 pacing_gain이 높은 값으로 설정됩니다. BBR이 ProbeBW 단계에 진입하면 사용 가능한 대역폭 추정치에 맞게 pacing_gain이 조정됩니다. 예상 BtlBw가 현재 전송률보다 낮으면 혼잡을 피하기 위해 pacing_gain이 감소합니다.
마찬가지로 ProbeRTT 단계에서는 RTprop을 더 정확하게 추정하기 위해 전송 중인 데이터 양을 제한하고 큐잉 지연을 줄이기 위해 pacing_gain이 조정됩니다. Drain 단계에서는 네트워크 버퍼에서 남은 데이터를 배출하고 추가 혼잡을 방지하기 위해 pacing_gain을 줄입니다.
전반적으로 네트워크 조건에 따라 pacing_gain을 조정함으로써 BBR은 전송 속도를 조절하고 다양한 네트워크 시나리오에서 최적의 성능을 달성할 수 있습니다.
이제 BBR 혼잡 제어 알고리즘의 네가지 제어 상태에 대해 알아보겠습니다.
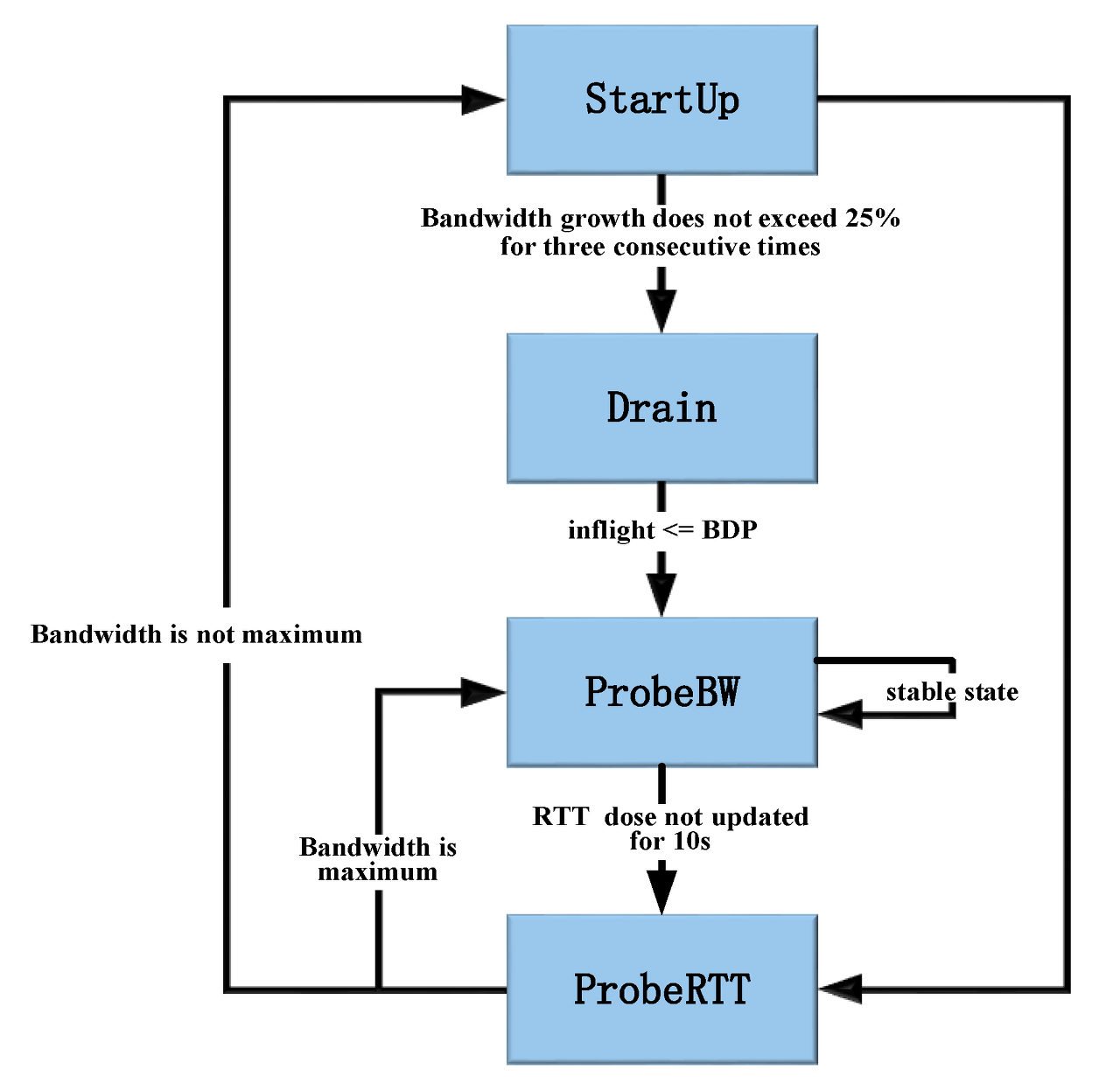
- StartUP
TCP의 slow start와 같습니다. 발신자는 전송 속도를 높이기 위해 pacing gain = 2/ln2 (약 2.85)로 설정하여 사용 가능한 최대 대역폭을 감지할 수 있습니다. 이 단계에서 약 2BDP의 중복 대기열을 생성할 수 있습니다. 새로 예측한 대역폭이 마지막 최대 대역폭의 1.25배를 연속 3회 초과하지 않으면 알고리즘은 링크가 완전히 채워진 것으로 간주하고 상태를 Drain으로 전환합니다. 이 상태는 사용 가능한 대역폭을 빠르게 채우고 병목 용량을 정확하게 예측하는 것을 목표로 합니다.
- Drain
링크의 패킷이 BDP와 일치할 때까지 전송 속도를 낮추기 위해 Drain의 pacing gain 이 ln2/2로 변경된 다음 상태가 Drain에서 RrobeBW로 변경됩니다. 다른 플로우를 위한 공간을 확보하거나 버퍼의 오버플로를 방지하기 위해 점차적으로 전송 속도를 낮추는 드레인 상태로 들어갑니다. 이 상태는 버퍼 오버플로로 인한 불필요한 패킷 손실을 방지하는 데 도움이 됩니다. StartUp과 Drain 이후 최대 전송률과 최소 RTT를 얻습니다.
- ProbeBW
ProbeBW 동안 pacing_gain은 서로 다른 값인 [1.25; 0.75; 1; 1; 1; 1; 1; 1]로 8주기를 거치며, 각 주기는 RTTmin 동안 지속됩니다.
pacing gain이 1.25인 ProbeUP 단계는 더 많은 가용 대욕폭을 프로핑하기 위해 전송속도를 높이고 pacing gain이 0.75인 프로브 다운 단계는 이전 프로빙에서 누적 초과된 큐를 제거하기 위한 단계입니다. 그런 다음 나머지 6 주기 동안 pacing gain을 1로 설정하여 전송속도를 안정화합니다. 또한 probeUP 단계에서 충분한 데이터 패킷을 전송 할 수 있도록 ProbeBW의 cwnd_gain을 2로 설정합니다. 10초 이내에 새로운 RTTmin이 다시 샘플링 되지 않으면 링크가 혼잡 상태에 빠진 것으로 간주하고 RrobeRTT로 들어갑니다.
이 상태에서 BBR은 네트워크를 탐색하여 정체 또는 패킷 손실을 감지할 때까지 전송 속도를 서서히 높여 사용 가능한 최대 대역폭을 찾습니다. 이 상태는 사용 가능한 대역폭을 정확하게 예측하는 데 도움이 되며 사용 가능한 용량을 효율적으로 활용할 수 있습니다.
- ProbeRTT
ProbeRTT에서 CWND는 가능한 모든 대기열을 제거하기 위해 매우작은 값(4XMSS)으로 설정되며 이 상태는 샘플링할 새 값 RTTmin을 보장하기 위해 200ms 동안 지속됩니다.이 상태에서 BBR은 네트워크의 최소 왕복 시간(RTT)을 추정하기 위해 네트워크를 조사합니다. 이 상태는 RTT를 정확하게 추정하고 그에 따라 전송 속도를 조정하여 버퍼가 과도하게 채워지는 것을 방지하는 데 도움이 됩니다. 이 프로세스가 끝나면 네트워크 대역폭이 꽉찼는지 여부에 따라 ProbeBW 또는 StartUp으로 전환됩니다.

BBR은 예상 병목 대역폭의 제곱근에 비례하고 예상 RTT에 반비례하는 속도로 패킷을 전송하는 방식으로 작동합니다. 이 접근 방식을 proportional rate reduction 라고 하며, 현재 네트워크 조건에 맞게 전송률을 최적화 합니다.
또한 BBR은 성능을 개선하고 지연을 줄이기 위한 몇가지 매커니즘이 포함되어 있습니다. 예를들어 application limited mode 를 사용하여 네트워크가 아닌 어플리케이션에 의해 전송속도가 제한되는 경우를 감지합니다. 또한 경쟁 트래픽으로 인한 네트워크 정체를 감지하고 복구하는 매커니즘도 포함되어있습니다.
* 다음의 글을 보고 작성하였습니다.
https://blog.acolyer.org/2017/03/31/bbr-congestion-based-congestion-control/
https://www.mdpi.com/2079-9292/10/5/615
https://squidarth.com/rc/programming/networking/2018/08/01/congestion-cubic.html
https://jacking75.github.io/network_Congestion_control_algorithm/
https://evan-moon.github.io/2019/11/26/tcp-congestion-control/
'논문 > QUIC' 카테고리의 다른 글
| [논문번역] Performance Analysis of TCP Congestion Control Algorithms (0) | 2023.03.08 |
|---|---|
| Network Simulator - NS-3 소개, 그리고 설치 방법 (0) | 2023.03.07 |
| [Congestion control] -혼잡제어에 대한 소개 (2) | 2023.02.23 |
| TCP의 window based Flow Contorl (흐름제어) (0) | 2023.02.21 |



