
minzzl
QUIC 프로토콜 이해 - 2장. 웹을 파헤치는 이유와 방법 본문
사실 HTTP에 대해 깊게 톺아보고 싶어 책 한권을 구매했습니다.. 그래서 앞으로는 그 책을 기반으로 블로그를 써내려갈 것 같습니다..
책 이름은 "러닝 HTTP/2 : 핵심만 쏙쏙, HTTP/2 적용 실무 가이드"이니 기회가 되면 꼭 ! 읽어보길 추천드립니다..
아주 내용이 탄탄합니다!
시작하겠습니다..
^^
우리는 HTTP/2 를 일상적으로 접해왔고 현재도 자주 접하고 있습니다. 최신 브라우저인 엣지, 사파리, 파이폭스, 크롬 등을 열고. 인스타그램, 페이스북과 같은 주요 웹사이트를 검색한다면 HTTP/2를 경험한 것입니다.
우리가 HTTP/2를 이해하기위해서는, 우리가 현재 있는 곳, 우리가 직면한 문제, 우리가 현재 그 문제를 다루고 있는 방법을 먼저 이해하는 것이 중요합니다.
1. 오늘날의 성능 문제
현대의 웹 페이지나 웹 애플리케이션을 전송하는 일은 결코 간단한 문제가 아닙니다. 페이지 내 수백 개의 개체, 수천 개의 도메인, 변동이 심한 네트워크, 광범위한 디바이스 기능이 존재하는 환경에서 일관되고 빠른 웹 경험을 만들어내는 것은 결코 쉬운 일이 아니기 때문입니다. 웹 페이지를 가져와서 렌더링 하는데 필요한 여러 단계뿐 아니라 단계마다 내재된 문제를 이해하는 것은 웹사이트와 상호 작용하는 사용자를 불편하지 않게 하는 데 가장 중요한 부분입니다. 또한 HTTP/2를 만든 이유를 이해하는 데 필요한 통찰력을 얻고, HTTP/2의 상대적 장점을 평사할 수 있을 것입니다.
1.1 웹페이지 요청의 구조
우리는 먼저 우리가 최적화 하려는 대상, 특히 사용자가 웹 브라우저에서 링크를 클릭한 때부터 화면에 웹 페이지가 표시될 때까지 일어나는 일을 기본적으로 이해하는 것이 중요합니다. 브라우저는 웹 페이지를 요청할 때, 화면에 페이지를 표시하는 데 힐요한 모든 정보를 가져오기 위해 반복적인 절차를 거쳐야만합니다. 이는 개체를 반입하는 로직과 페이지를 파싱/렌더링하는 로직, 두 부분을로 나누어 생각하는 게 더 쉽습니다. 반입 로직 먼저 살펴보겠습니다.

그 다음은 응답을 수신하여 페이지를 렌더링하는 절차를 보여줍니다.
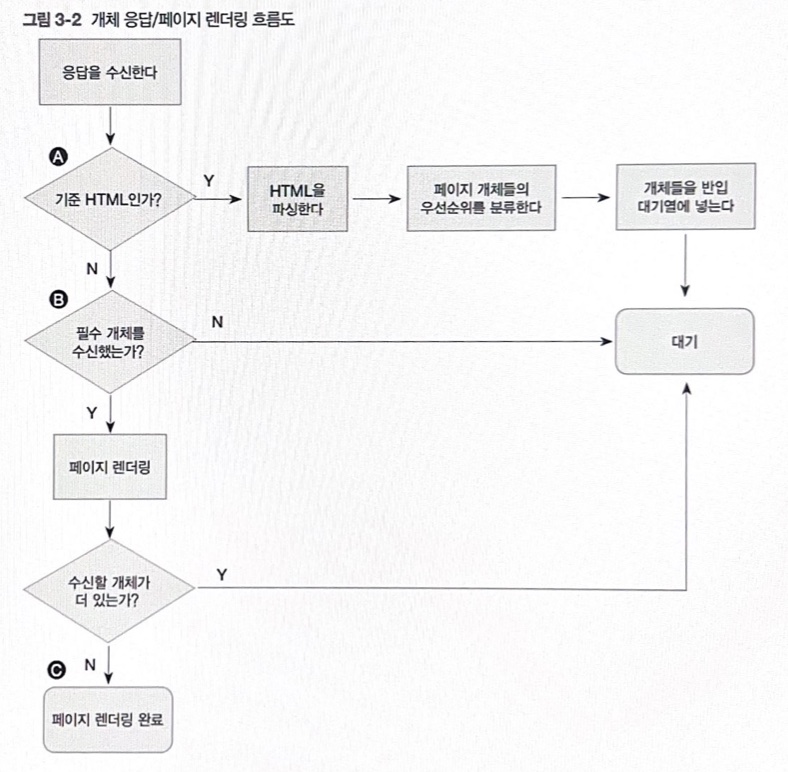
해당 절차는 페이지를 클릭 할 때마다 반복되어야만 합니다. 이 반복적인 절차는 네트워크와 디바이스 자원에 부담을줍니다. 이 중 어느 단계든 최적화하거나 제거하는 일이 웹 성능 튜딩이라는 예술에 핵심적인 부분이라고 할 수 있습니다.
1.2 중요 성능
앞의 두 그림에서 웹 성능에 중요한 부분과 앞으로 집중적으로 살펴봐야 할 부분을 이끌어낼 수 있습니다. 먼저 웹 페이지를 불러오는데, 전반적인 영향을 미치는 네트워크 수준의 지표부터 시작해봅시다.
- 지연시간
지연 시간이란 IP 패킷이 한 지점에서 다른 지점으로 이동하는 데 걸리는 시간을 말합니다. 이와 관련된 것으로 왕복 시간(RTT)이라는 것이 있으며, 지연 시간의 2배를 의미합니다. 지연 시간은 성능의 주요 병목점이며, 서버까지 많은 왕복이 이루어지는 HTTP 와 같은 프로토콜에서는 특히 그러합니다.
- 대역폭
두 지점 사이의 연결은 포화 상태가 되기 직전까지의 데이터양만 동시에 처리할 수 있습니다. 웹 페이지의 데이터양과 연결의 용량에 따라 대역폭이 성능의 병목점이 될 수도 있습니다.
- DNS 조회
클라이언트가 웹 페이지를 가져올 수 있으려면 인터넷의 전화번호부인 DNS를 사용해 호스트이름을 IP 주소로 변환해야한다. 이 절차는 가져온 HTML 페이지에 있는 모든 고유한 호스트이름에 대해 이루어져야하며, 다행히 호스트 이름 당 한번 만 하면된다.
- 연결 시간
연결을 수립하려면 클라이언트오아 서버 사이에 3-way handshake 라는 메시지 주고 받기가 필요합니다. 이 핸드 쉐이크 시간은 보통 클라이언트와 서버 사이의 지연시간과 관련이 있습니다. 핸드 셰이크를 위해서는 클라이언트가 서버로 SYN 패킷을 전송하고, 서버는 그 SYN에 대한 서버의 ACK와 SYN 패킷을 클라이언트를 전송하며, 클라이언트는 다시 SYN에 대한 ACK를 서버로 전송합니다.
- TLS 협상 시간
클라이언트가 HTTPS 연결을 하고 있다면 SSL의 후속 프로토콜인 TLS협상이 필요합니다. 이 때문에 서버와 클라이언트의 처리 시간에 왕복 시간이 더 추가됩니다. 이 시점에서 클라이언트는 아직 요청을 보내지도 않았으며, DNS 왕복 시간과 TCP와 TLS를 위한 추가 시간이 이미 소요되었습니다.
다음으로 네트워크보다는 서버 자체의 내용이나 성능에 좀더 의존적인 지표를 살펴보겠습니다.
- TTFB(Time To First Byte)
TTFB는 클라이언트가 웹 페이지 탐색을 시작한 때부터 기준 페이지 응답의 첫 번째 바이트를 수신한 때까지 걸린 시간을 측정하는 것입니다. 이것은 서버의 처리 시간뿐만 아니라 앞서 소개한 여러 지표를 합한 값입니다. 한 페이지에 여래 개체가 있는 경우, TTBT는 브라우저가 요청을 전송한 시점부터 첫번째 바이트가 되돌아온 시점 까지의 시간을 측정합니다.
- 콘텐츠 다운로드 시간
이것은 요청한 개체에 대한 TTLB(Time To Last Byte)입니다.
- 렌더링 시작 시간
클라이언트가 사용자를 위해 얼마나 빨리 화면에 무언가를 표시할 수 있는가? 이것은 사용자가 얼마나 오랬동안 빈페이지를 바라보았는지를 측장한 것입니다.
- 문서 완성 시간
이것은 클라이언트가 페이지 표시를 완료한 시간입니다.
웹성능을 들여다 볼 때, 특히 더 빠르게 동작하는 새로운 프로토콜을 만드는 것이 목적이라면 이 지표들을 반드시 염두해두어야만 합니다. HTTP/1.1이 직면한 문제들과 다른 무언가가 필요한 이유를 논의할 때 이들을 다시 참조할 것입니다.
이 지표들 외에도, 인터넷은 성능상의 병목을 유발하는 요소들이 갈수록 증가하고 있습니다. 다음은 이러한 요소들 중 기억해야한 것입니다.
- 바이트 수의 증가
- 개체 수의 증가
- 복잡도의 증가
- 호스트 수의 증가
- TCP 소켓 수의 증가
매년 페이지크기, 이미지크기, CSS 크기가 증가하고 있는 것은 자명합니다. 즉 내려받을 바이트 수가 많아지고 페이지 로딩 시간이 더 오래걸립니다.
뿐만아니라 개체수는 점점 많아지고 있으므로 모든 것을 가져와 처리하는데 전체적으로 더 오랜 시간이 걸립니다.
더 많고 풍부한 기능을 추가할 수록 페이지와 그 종속 개체들은 점점 더 복잡해집니다. 복잡해질수록 페이지를 계산하고 렌더링하는 시간이 늘어나며, 처리 능력이 떨어지는 모바일 디바이스에서 특히 더 그러합니다.
웹 페이지는 개별 호스트에서 가져온 것이 아닐뿐더러 대부분의 페이지는 수 많은 참조 호스트가 있습니다. 각 호스트 이름은 추가적인 DNS 조회시간, 연결시간, TLS 협상 시간을 의미합니다.
이러한 증가하는 요소들을 해결하기 위해 클라이언트는 호스트마다 여러개의 소켓을 엽니다. 이는 호스트당 연결 협상 오버헤드를 증가시키고, 디바이스의 부하를 가중시키며, 잠재적으로 네트워크 연결 과부화를 일으켜, 재전송과 버퍼블로트로 인한 실효 대역촉 저하를 유발합니다.
1.3 HTTP/1 의 문제점
HTTP/1은 우리를 현재의 웹 환경으로 이끌어주었지만 그 설계상의 한계로 현대 웹의 요구를 충분히 충족시키지는 못하고 있습니다.
다음은 HTTP/1 프로토콜이 가진 중요한 문제이자 결국 HTTP/2가 설계적으로 해결한 핵심 문제들입니다.
1) HOL 블로킹
브라우저는 특정 호스트에서 단 하나의 개체만 가져오려고 하지 않습니다. 브라우저는 대개 한번에 많은 개체를 가져오려고 합니다. 특정 도메인에 모든 이미지를 넣어둔 웹사이트 하나를 생각해봅시다. HTTP/1은 그 이미지들을 동시에 요청하는 어떠한 메커니즘도 제공하지 않습니다. 단일 연결상에서는 브라우저는 요청 하나를 보내고 그 응답을 수신한 후에야 또 다른 요청을 보낼 수 있습니다. HTTP/1은 브라우저가 많은 요청을 한번에 보낼 수 있게 해주는 파이프라이닝이라는 기능이 있지만, 브라우저는 여전히 전송된 순서대로 하나씩 응답을 수신합니다. 추가로, 파이프라이닝은 상호 운용성과 배포 측면에서 사용하기 어렵게하는 여러 문제가 있습니다.
이러한 여러 요청이나 응답 중 어디엔가 문제가 발생하면 그 요청/응답을 뒤따르는 다른 모든 것들은 막혀버립니다. 이 현상을 HOL 블로킹이라고 합니다. 이 때문에 웹이지의 전송과 렌더링이 중단될 수 있습니다. 요즘 브라우저는 특정 호스트에 최대 6개의 연결을 열고 각 연결로 요청을 전송해 어느 정도 병렬 처리가 가능합니다. 각 연결은 여전히 HOL 블로킹의 영향을 받을 수 있습니다. 게다가 이는 제한된 디바이스 자원을 적절히 사용하는 방법이 아닙니다.
그렇다면 제한된 디바이스를 적절히 사용하기 위해서는 어떻게 해야할까요?
2) TCP의 비효율적 사용
TCP는 보수적인 환경을 가정하고 네트워크 상의 다양한 트래픽 용도에 공평하게 동작하도록 설계되었습니다. 보수적인 환경을 가정했다는 것은, TCP는 혼잡회피 매커니즘은 최악의 네트워크 상태에서 동작하도록 만들어졌고, 경쟁적인 요구가 있는 환경에서 비교적 공평하게 작동합니다. 즉 TCP가 이제껏 자리매김 할 수 있었던 것은 TCP가 데이터를 가장 신뢰성있게 전송시켜주었기 때문입니다.
여기서 핵심은 혼잡 윈도우(Congestion window)라는 개념입니다. 혼잡 윈도우는 수신자가 확인 응답인, ACK를 주기 전까지 송신자가 전송할 수 있는 TCP 패킷의 수를 의미합니다.
만약 혼잡 윈도우가 1로 설정되어 있다면, 송신자는 단 하나의 패킷만을 전송하며 그 패킷에 대한 수신자의 확인을 받아야만 또 다른 패킷을 전송할 수 있습니다.
패킷이란?
TCP 통신에 필요한 여러 항목을 정의하고 있는 구조로 Bytes의 모음이다.
패킷의 페이로드 하나에 넣을 수 있는 가장 큰 데이터의 크기는 1460bytes이다.
그런데 한 번에 하나의 패킷만을 전송하는 것은 매우 비효율적임을 우리는 알고 있다. TCP는 현재 연결에 알맞은 혼잡 윈도우의 크기를 결정하기 위한 Slow Start라는 개념을 사용한다. Slow Start의 설계 목적은 새로운 연결이 네트워크의 상태를 감지해 이미 혼잡한 네트워크를 악화시키지 않게 하는 것입니다. Slow Start를 통해 송신자는 ACK를 수신할 때마다 패킷의 수를 늘려서 전송할 수 있습니다. 이는 새로운 연결에서 첫 번째 ACK를 수신한다음 송신자는 두개의 패킷을 전송할 수 있으며 그 두개의 패킷이 확인 되면 다시 네개의 패킷을 전송할 수 있음을 의미합니다. 이 기하급수적인 증가는 얼마 되지 않아 프로토콜에 정의된 상한 선에 도달하며 그 시점에 이 연결은 이른바 혼잡회피 단계로 들어갈 것 입니다.

최적의 혼잡 윈도우 크기를 얻는 데에는 몇번의 왕복이 필요합니다. 또한 성능 문제를 해결하는데 그 몇번의 왕복은 매우 중요한 시간입니다. 현재의 운영체제는 보통 4에서 10의 초기 혼잡 윈도우 크기를 사용합니다. 패킷의 크기가 약 1460 bytes 라면 송신자는 5840 bytes( 1460 bytes X 4 )만 전송한 후 ACK를 기다려야합니다. 요즘의 웹 페이지는 HTML과 모든 종속 개체를 포함해 평균 약 2MB의 데이터가 있습니다. 이상적인 환경에서 운이 따라준다면, 이는 페이지를 전송하는데 약 9번의 왕복이간이 소요될 것입니다.
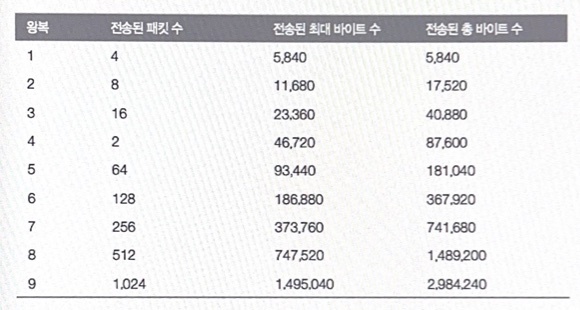
게다가 브라우저는 특정 호스트에 대해 보통 6개의 연결을 열고 있으므로, 각 연결마다 이러한 혼잡제어를 해야합니다.
HTTP/1은 다중화를 지원하지 않기 때문에, 브라우저는 특정 호스트에 보통 6개의 연결을 합니다. 이는 혼잡 윈도우 널뛰기가 동시에 6번 일어나야함을 의미합니다. TCP는 이 연결들이 함께 잘 동작하게해주지만 이들이 최적의 성능을 발취하도록 보장하지는 못합니다.
3)비대한 메시지 헤더
HTTP/1은 요청된 개체를 압축하는 매커니즘을 제공하기는 하지만 메시지 헤더를 압축하는 방법은 없습니다.
실제로 헤더는 크기가 증가할 수 있습니다. 응답 패킷에서는 개체 크기 대비 헤더 크기의 비율이 매우 낮지만, 요청 패킷에서는 헤더가 대부분의 바이트를 차지합니다. 쿠키가 있는 경우 요청 헤더의 합이 수 킬로 바이트 크기로 커지는 것은 이상한 일이 아닙니다.
HTTP 아카이브에 따르면, 2016년 말, 요청 헤더의 평균 크기는 약 460 bytes라고 합니다.
140개의 개체가 있는 일반적인 웹페이지의 경우, 요청 헤더의 전체크기는 약 63KB가 됩니다. TCP 혼잡 윈도우 제어에 관한 논의를 다시 떠올려보면, TCP가 해당 개체에 대한 요청을 보내는데만 3-4번의 왕복이 필요할 수 있습니다. 네트워크 지연으로 인한 손해는 빠르게 누적되기 시작합니다. 또한, 업로드 대역폭은 보통 네트워크의 제약을 받기 때문에 혼잡 윈도우의 크기가 처음부터 충분하지 않아 더 많은 왕복을 유발할 수 있습니다.
헤더의 압축 기능이 없기 때문에, 클라이언트가 대역폭 제한에 걸릴 수도 있습니다. 이는 저대역폭 또는 과밀 링크에서는 더욱 그러합니다.
대표적인 예가 Stadium Effect입니다. 수만명의 사람들이 동시에 같은 장소에 있을 때, 모바일 통신 대역폭은 빠르게 소진됩니다. 헤더를 압축하여 요청의 크기를 줄이면 이와 같은 상황에서 도움이 되며 시스템 부하도 전반적으로 줄어들 것입니다.
4)제한적인 우선 순위
브라우저가 하나의 호스트에 다수의 소켓을 열고 개체를 요청하기 시작할 때, 그 요청들의 우선순위를 지정하기 위한 옵션은 매우 제한적인데, 그것은 바로 요청을 보내거나 보내지 않거나 둘 중 하나입니다.
페이지에서 어떤 개체는 다른 개체보다 훨씬 더 중요합니다. 브라우저는 높은 우선순위의 개체를 먼저 가져오려고 다른 개체에 대한 요청을 보류하는데, 그러는 동안 우선 순위 개체들은 줄줄이 대기 상태에 빠집니다. 이로 인해 브라우저가 높은 우선 순위 항목을 기다리는 동안 서버는 낮은 우선순위 항복을 처리 할 기회를 얻지 못해 페이지 다운로드 시간이 전체적으로 길어질 수 있습니다. 또는 브라우저가 페이지를 처리하는 방식때문에 브라우저가 높은 우선순위 개체를 발견했어도 이미 반입된 낮은 우선순위 항목 뒤에서 높은 우선순위 개체가 막혀버리는 경우도 있습니다.
5)서드 파티 개체
특별히 HTTP/1의 문제점은 아니지만, 성능 문제로 대두되고 있는 것입니다.
현대 웹페이지에서 요청되는 것 중에는 웹 서버의 제어 범위에서 완전히 벗어나 있는 것들이 많으며 이를 서드파티 개체라고 합니다. 서드 파티 개체의 탐색과 처리는 보통 요즘의 웹페이지를 불러오는데 소요되는 시간의 절반을 차지합니다. 서드 파티 개체가 페이지 성능에 미치는 영향을 최소화하려는 기법이 많이 있습니다. 하지만 웹 개발자가 직접 제어할 수 있는 범위를 벗어난 콘텐츠가 많은 경우, 그 개체들 중 일부는 성능을 저하시키고 페이지 렌더링을 지연 또는 중단시킬 가능성이 있습니다. 웹 성능에 관한 어떠한 논의도 이 문제를 언급해야만 합니다. 사실 HTTP/2도 이 문제를 해결한 해결책을 찾지 못했습니다.
2. 웹 성능 기법
대부분의 사업에서 웹사이트를 보유하는 것이 중요해지면서, 웹 사이트 성능을 이해하고, 측정하고, 최적화하는 일이 중요해지고 있습니다.
계속 언급해왔듯이, 브라우저 시간의 대부분은 콘텐츠를 가져와 클라이언트에서 페이지를 렌더링하는데에 소요됩니다.

따라서 웹 개발자들은 클라이언트의 네트워크 지연을 줄이고 페이지 렌더링 시간을 최적화하는 방식으로 성능을 개선하는데 더욱 집중합니다. 시간은 돈이기 때문입니다.
2.1 웹 성능 모범 사례
1) DNS 조회를 최적화하라
DNS 조회는 호스트와 연결이 수립되기 전에 이루어져야 하므로, 이 조회 절차는 가능한 빨라야합니다.
- 고유한 도메인/호스트이름의 수를 제한해라.
- 조회 지연 시간을 줄여라.
- 초기 HTML 이나 응답에 대해 DNS 프리패치를 활용해라. 이는 초기 HTML을 내려받아 처리하는 동안 그 페이지에 있는 특정 호스트이름들을의 DNS 조회를 시작할 것입니다.
이 기법들은 DNS의 고정적인 오버헤드를 최소화하는데 도움을 줍니다.
2) TCP 연결을 최적화 하라
새 연결을 여는 일은 시간이 오래 걸리는 절차일 수 있습니다. 연결이 TLS를 사용하는 경우라면, 그 오버레드는 훨씬 큽니다. 이 호버헤드를 줄이는 방법은 다음과 같습니다.
- preconnect를 활용하라. 필요하기 전에 미리 연결을 수립해둠으로써 waterfall critical path에서 연결 시간을 제거해줍니다.
- 조기 종료를 사용하라. 콘텐프 전송 네트워크를 활용하면, 요청하는 클라이언트와 가까이 위치한 인터넷 경계에서 연결을 종료시킬 수 있으며 결국 새로운 연결을 수립할 때 수반되는 왕복지연을 최소화할 수 있습니다.
- HTTPT를 최적화하기 위해 최신 TLS 모번 사례를 실행해라
많은 자원을 동일한 호스트에 요청하는 경우, 클라이언트 브라우저는 자원을 가져올 때의 병목을 피하려고 자동으로 서버와 병렬 연결을 열것입니다. 현재 대부분의 클라이언트 브라우저는 6개 이상의 병렬 연결을 지원하지만, 브라우저가 특정 호스트에 여는 병령 연결의 수를 사용자가 직접 제어할 수는 없습니다.
3) 리다이렉션을 피하라
리다이렉션은 보통 다른 호스트로 연결을 하게 하며, 이는 추가적인 연결이 수립되어야함을 의미합니다. 무선 네트워크에서 추가 다이렌션은 수백 ms의 지연을 증가 시킬 수 있으며 이는 사용자 경험에 나쁜 영향을 미치고 결국 웹사이트를 운영하는 기업에도 해가됩니다. 특별한 상황을 제외하고는 리다이렉션을 할만한 타당한 이유가 없습니다.
4) 압축과 축소화
텍스트 형태의 모든 콘텐츠(HTML, JS, CSS, SVG .. )는 압축과 축소화의 혜택을 볼 수 있습니다.
이 두 방법을 함께 사용하면 개체의 크기를 대폭 줄일 수 있습니다. 더 적은 바이트 수는 더 적은 왕복을 의미하며, 이는 결국 시간도 덜 소요됨을 의미합니다.
축소화는 텍스트 개체에서 불필요한 모든 요소를 제거하는 절차입니다. 일반적으로 이러한 개체들은 사람이 쉽게 읽고 관리할 수 있는 방식으로 만든 것입니다만, 브라우저는 가독성에는 아무런 관심이 없기에 그 가독성을 포기하면 공간을 절약할 수 있습니다.
예를 들면 아래와 같습니다.
<html>
<head>
<!--Change the title as you see fit-->
<title>My first web page</title>
</head>
<body>
<!--Put your message of the day here-->
<p>Hello, World!</p>
</body>
</html>이를 축소하면 아래와 같습니다.
<html><head><title>My first web page</title></head><body>
<p>Hello, World!</p></body></html>물론 가독성은 떨어지지만, 바이트 수는 절반으로 줄었습니다.
압축은 축소된 개체를 한 번 더 줄일 수 있습니다. 압축은 손실 없이 복원할 수 있는 알고리즘을 사용해 개체의 크기를 줄입니다. 서버는 개체를 전송하기 전에 압축해 전송 바이트 수를 90%까지 줄입니다. 흔히 사용하는 압축 방식에는 gzip과 디플레이트가 있으며 브로틀리처럼 비교적 최근에 등장한 방식도 있습니다.
5) CSS/JS 차단을 피하라
CSS는 화면에 콘텐프를 렌더링하는 방법과 위치를 클라이언트 브라우저에 알려줍니다. 따라서 클라이언트는 화면에 첫 번째 픽셀을 그리기 전에 모든 CSS를 내려받아야합니다. 브라우저의 프리파서는 매우 지능적이어서 CSS를 어디에 두든 전체 HTML에서 필요한 모든 CSS를 미리 가져올 수 있습니다.
기본적으로 JS는 HTML 내의 코드가 위치한 지점에서 반입되어 파싱되고 실행되며, 브라우저가 이 작업을 완료할 때까지 해당 JS가 위치한 지점 이후에ㅔ 있는 모든 자원은 다운로드와 렌더링이 차단됩니다. 경우에 따라서는 특정 JS를 내려받아 실행하는 동안 HTML 나머지 부분의 파싱과 실행을 차단하는 것이 나을 수도 있습니다.
하지만 이러한 기본적인 차단 동작은 대게 불필요한 지연을 발생시키고, 심지어 단일 장애점을 유발할 수도 있습니다. JS 차단의 잠재적인 역효과를 줄이려면 직접 제어할 수 있는 콘텐프와 직접 제어하지 못하는 서드파티 콘텐츠에 각각 다른 전략을 수립하는 것이 좋습니다.
- JS의 실행순서는 중요하되 DOM 로딩이 된 후에 JS를 실행해도 된다면, defer 속성을 사용하라
- JS가 초기 화면 구성에 충요하지 않다면 onload 이벤트가 발생한 후에 JS를 가져와서 처리하는 것이 좋다.
- 메인 onload 이벤트를 지연시키고 싶지 않다면, 메일 페이지와는 별개로 처리되는 iframe을 통해 JS를 가져오는 것을 고려할 수 있다.
onload
문서의 모든 콘텐츠(images, script, css, etc)가 로드된 후 발생하는 이벤트
6) 이미지를 최적화하라
현대의 웹사이트들은 이미지로 가득 차 있기 때문에, 이미지를 최적화하면 성능상의 이득을 가장 많이 볼 수 있습니다. 이미지 최적화는 최소한의 바이트 수만으로 원하는 시간 품질을 달성하는 것을 목표로 합니다.
- 피사체 위치, 타임스탬프, 이미지크기, 해상도와 같은 메타데이터는 보통 이진 정보로 담겨 있으며, 클라이언트에 제공하기 전에 제거해야한다.
- 이미지 오버로딩이란 이미지의 원본 크기가 브라우저의 창 크기를 넘거나 이미지 해상도가 디바이스 화면의 한계를 넘어, 브라우저에 의해 이미지의 크기가 자동으로 줄어드는 것을 말한다. 이렇게 브라우저에서 이미지가 축소되는 것은 대역폭, CPU 자원을 낭비하는 것이다.
이미지 오버 로딩을 줄이는 방법은 사용자의 디바이스, 네트워크 상태, 기대 화질에 맞추어 이미지를 제공하는 것입니다.
2.2 안티 패턴
HTTP/2는 호스트마다 하나의 연결만 열기 때문에 HTTP/1.1의 모범 사례 중 일부는 HTTP/2에서 안티패턴으로 바뀝니다.
HTTP/2 웹사이트에는 더 이상 적용되지 않는 인기있는 방법 몇가지를 알아봅시다.
1) 스프라이팅과 자원통합/인라이닝
스프라이팅은 작은 이미지 여러 개를 큰 이미지 하나로 통합하여 여러개의 이미지 요소를 단 한번만 요청 할 수 있게 하는 것을 말합니다.
더 이상 특정 요청으로 인해 무언가가 준단되는 일 없이 많은 요청을 병렬로 처리 할 수 있는 HTTP/2에서, 스프라이팅은 성능적인 면에서 더 이상 고려할 가치가 없습니다. 또한 웹사이트 관리자는 더 이상 스프라이트를 만들 걱정을 할필요가 없습니다.
같은 맥락으로, 클라이언트와 서버 간의 연결 수를 줄이기 위해 JS와 CSS 같은 소규모 텍스트 자원들로 더 큰 단일 자원으로 통합하거나 메인 HTML에 직접 포함할 수 있습니다. 한가지 역효과로 독립적으로 캐싱할 수 있는 CSS나 JS를 캐싱할 수 없는 HTML에 포함하면 근복적으로 캐싱할 수 없게 되어 버리므로 사이트를 h1에서 h2로 마이그레이션 하는 경우에는 이 방법을 피해야합니다.
2) 샤딩
샤딩은 호스트 이름마다 다수의 연결을 열어 콘텐츠를 병렬로 내려받는 브라우저의 기능을 활용하는 것입니다.
즉 브라우저가 더 많은 소켓을 사용할 수 있도록 개체들을 다수의 도메인으로 분산하는 패턴입니다.
HTTP/2는 단일 소켓을 사용하도록 설계되어, 샤딩을 사용하면 이 설계 목적을 훼손하게 됩니다.
하나의 소켓을 열고 적절한 혼잡도에서 동작하는 것이 다수의 소켓을 조율하는 것보다 훨씨 더 신뢰성있고 성능이 좋다고 봅니다. 물론 사이트 구성에 따라 여러소켓이 단일 소켓보다 나은 경우가 여전히 있기는 합니다.이는 TCP 혼잡제어가 동작하는 방식과 최적의 설정으로 맞춰지는데 걸리는 시간이 있기 때문입니다. 초기 혼잡 윈도우의 크기가 매우 크면 이 문제를 줄이는데 도움이 되지만, 큰 윈도우를 지원하지 못하는 네트워크에서는 문제가됩니다.
3) 쿠키 없는 도메인
HTTP/1에서는 요청과 응답 헤더의 내용은 압축되지 않습니다. 시간이 갈 수록 헤더의 크기가 커지고 있기 때문에 TCP 패킷하나보다 쿠키 크기가 더 큰 경우는 더 이상 이상한 일이 아닙니다. 결과적으로 서버와 클라이언트 사이에 헤더 정보가 오가는 동안 무시할 수 없을 만큼 지연이 발생할 수 있습니다.
따라서 쿠키 없는 도메인을 만드는 것은 꽤 합리적인 권고사항이었습니다.
하지만 HTTP/2에서는 헤더를 압축할 수 있었을 뿐더러 이미 알려진 정보를 전송하지 않기 위해 양 단에 헤더이력을 저장합니다. 따라서 HTTP/2로 사이트를 재설계하면 쿠키 없는 도메인을 만들지 않아도 되므로 삶이 더 편해집니다.
다수의 정적 개체를 동일한 호스트 이름에서 HTML로 제공하면 그 정적 자원들을 가져오는 것을 지연시키는 추가적인 DNS 조회와 소켓 연결을 피할 수 있습니다. 렌더링을 중단시킬 수 있는 자원을 동일한 호스트 이름에서 HTML로 전송하면 성능을 개선할 수 있습니다.
3. 요약
HTTP/2의 목표 중 하나는 이렇듯 꽤 복잡한 성능 최적화 기법을 사용하지 않고 웹 성능을 개선하는 것입니다.
물론 그 전에 그러한 기법들과 그 등장 이유를 알게 된다면 웹과 웹 동작 방식을 더욱 잘 이해할 수 있겠죠 ..
'논문 > QUIC' 카테고리의 다른 글
| [Congestion control] -혼잡제어에 대한 소개 (2) | 2023.02.23 |
|---|---|
| TCP의 window based Flow Contorl (흐름제어) (0) | 2023.02.21 |
| 리눅스 tc 명령어 사용법 (0) | 2023.02.19 |
| QUIC 프로토콜 이해 - 1장. HTTP 역사와 HTTP2 (0) | 2022.12.01 |


