
minzzl
[프로그래머스] - 정렬. K번째 수 본문
안녕하세요 !
오늘 아침에 Heap을 끝내고 정렬로 넘어왔습니다 !!!
사실 코테만 준비하면 지금보다 더 일찍 끝낼 수 있을 것 같은데 논문 작업을 해야하기 때문에 계속 미뤄지게되네욥 ...
그치만 이번주에는 코테에 시간을 투자해보려고 합니다!!!
저의 목표로는 이번주에 프로그래머스 기본적인 문제를 끝내고 다음 주 부터는 백준으로 넘어가서 하루에 한문제 정도 풀면서 연구실 일을 시작하려고 합니당
주변에 다들 코테 정도는 안정적일정도로 준비했다고 하는 것 같아서 너무 너무 쪼달리지만 ^^
어떻게든 되겟죠 ... ?
할 수 있다 !!!!
문제
풀이
사실 아주 직관적으로 풀었기 때문에 어려움은 없었습니다.
파이썬 리스트는 arr[index: index'] 형태로 리스트를 새로 반환할 수 있기 때문에 리스트를 다루는데도 큰 문제가 없었고,
list의 내장 함수인 sort 를 사용하여 정렬하였기에 아주 간단했습니다.
다만 arr[index: index'] 부분이 약간 헷갈려서 이번 기회에 정리해보겠습니다 !
리스트의 슬라이싱
리스트 슬라이싱은 파이썬의 가장 유용한 기능 중 하나이다.

위의 그림과 같이 1부터 8까지 여덟개 숫자를 포함하는 리스트가 있다.
파이썬에서는 아래와 같이 start, stop, step 세 개의 숫자를 사용해서 리스트를 다양하게 슬라이싱할 수 있다.

- start를 입력하지 않으면 0을 입력한 것과 같다.
- stop을 입력하지 않으면 len(my_list)를 입력한 것과 같다.
- step을 입력하지 않으면 1을 입력한 것과 같다.
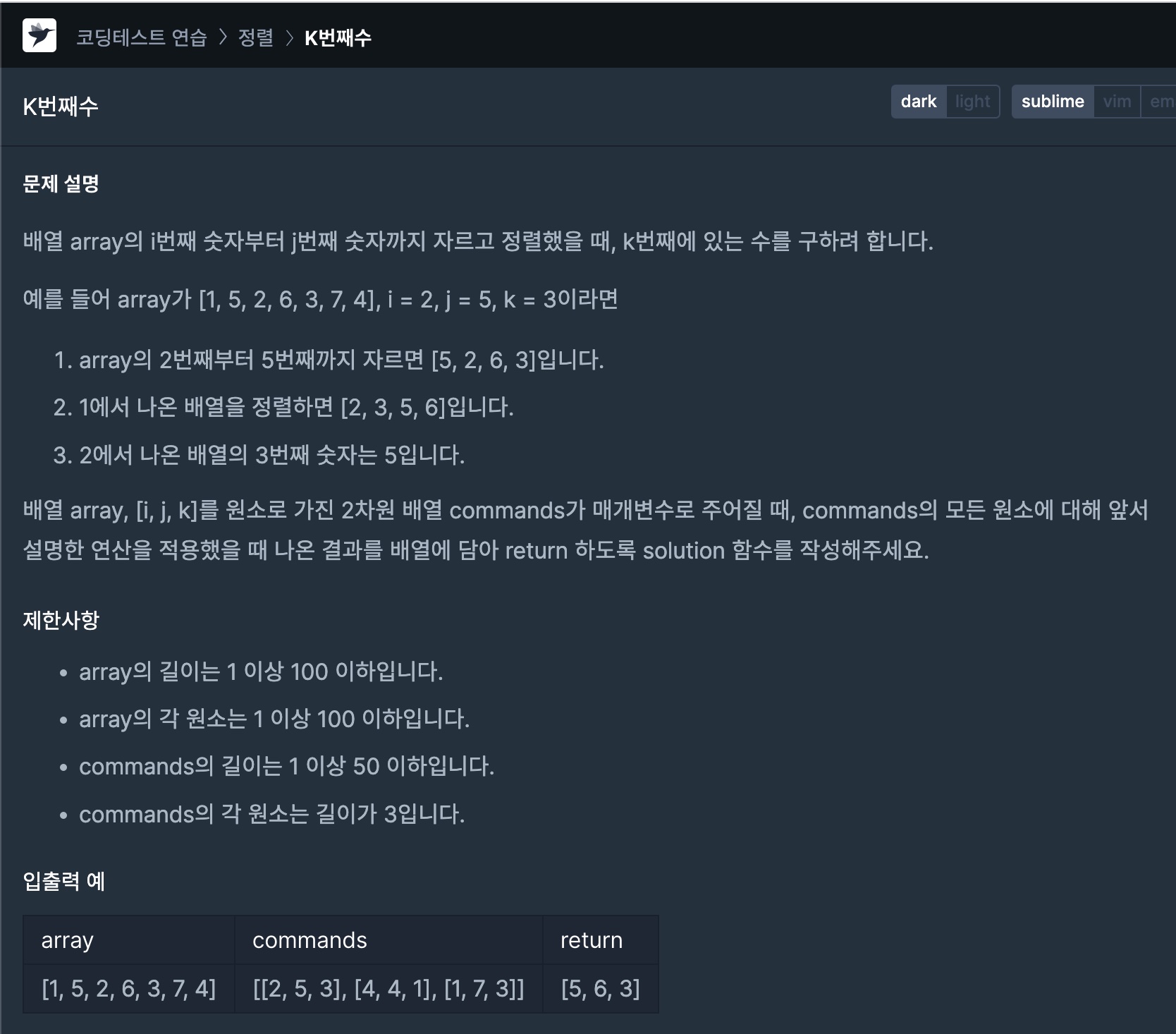
1) 시작, 끝 지점 사용하기
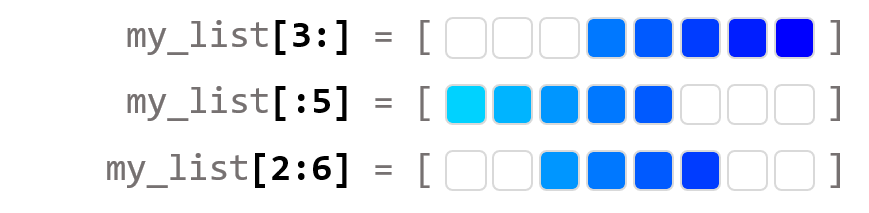
my_list = [1, 2, 3, 4, 5, 6, 7, 8]
print(my_list[3:])
print(my_list[:5])
print(my_list[2:6])
>> [4, 5, 6, 7, 8]
>> [1, 2, 3, 4, 5]
>> [3, 4, 5, 6]
my_list[3:] 은 리스트의 인덱스 3의 위치에서 끝까지 슬라이싱한다.
앞에서 3개의 성분을 제외한 것과 같다.
my_list[:5] 는 리스트의 처음부터 인덱스 5의 위치까지 슬라이싱한다.
앞에 5개의 성분을 선택하는 것과 같다.
my_list[2:6] 은 리스트의 인덱스 2의 위치에서 6의 위치까지 슬라이싱한다.
앞에서 6개를 선택하고 2개를 제외하는 것과 같다.
2) 음의 인덱스 사용하기
my_list = [1, 2, 3, 4, 5, 6, 7, 8]
print(my_list[:-2])
print(my_list[-4:])
print(my_list[-5:-2])
>> [1, 2, 3, 4, 5, 6]
>> [5, 6, 7, 8]
>> [4, 5, 6]my_list[:-2]는 리스트의 처음부터 인덱스 -2의 위치까지 슬라이싱한다.
뒤에서 2개의 성분을 제외하는 것과 같다.
my_list[-4:] 는 리스트의 인덱스 -4의 위치에서 끝까지 슬라이싱한다.
뒤에서 4개 성분을 선택하는 것과 같다.
my_list[-5:-2] 은 뒤에서 5개를 선택하고 2개를 제외하는 것과 같다.
3) 리스트 복사하기

my_list = [1, 2, 3, 4, 5, 6, 7, 8]
print(my_list[:])
>> [1, 2, 3, 4, 5, 6, 7, 8]
my_list[:]은 리스트의 처음부터 끝까지 슬라이싱한다.
리스트 전체를 복사하는 것과 같으며, 이는 얕은 복사(Shallow copy)에 해당한다.
4) 간격 (step) 사용하기

my_list = [1, 2, 3, 4, 5, 6, 7, 8]
print(my_list[::2])
print(my_list[::3])
>> [1, 3, 5, 7]
>> [1, 4, 7]
my_list[::2] 은 리스트의 처음부터 끝까지 간격 2 단위로 슬라이싱한다.
my_list[::3] 은 리스트의 처음부터 끝까지 간격 3단위로 슬라이싱한다.
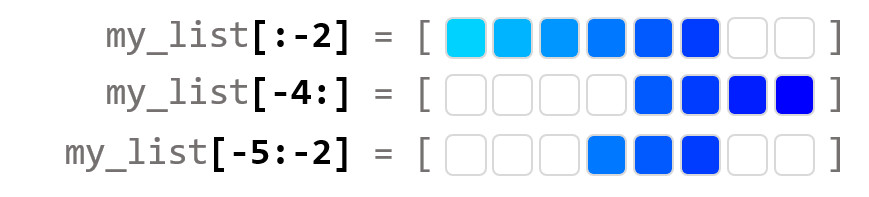
5) 시작(start) / 끝(stop) / 간격(step) 사용하기
my_list = [1, 2, 3, 4, 5, 6, 7, 8]
print(my_list[1::2])
print(my_list[1::3])
print(my_list[2:6:2])
>>[2, 4, 6, 8]
>>[2, 5, 8]
>>[3, 5]my_list[1::2]은 리스트의 인덱스 1의 위치에서 끝까지 간격 2 단위로 슬라이싱한다.
my_list[1::3]은 리스트의 인덱스 1의 위치에서 끝까지 간격 3 단위로 슬라이싱한다.
my_list[2:6:2]은 리스트의 인덱스 2의 위치에서 인덱스 6의 위치까지 간격 2 단위로 슬라이싱한다.
6) 음의 간격 (step) 사용하기
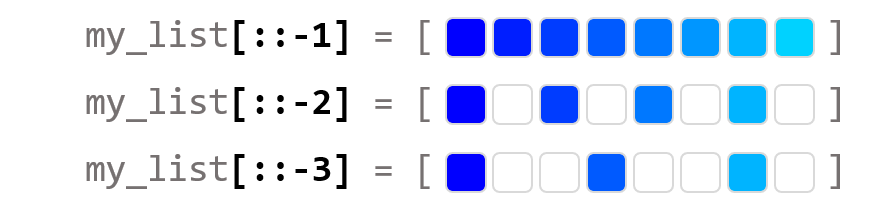
my_list = [1, 2, 3, 4, 5, 6, 7, 8]
print(my_list[::-1])
print(my_list[::-2])
print(my_list[::-3])
>>[8, 7, 6, 5, 4, 3, 2, 1]
>>[8, 6, 4, 2]
>>[8, 5, 2]my_list[::-1]은 리스트의 처음부터 끝까지 간격 -1 단위로 슬라이싱한다.
뒤집어진 리스트 전체를 복사하는 것과 같다.
마찬가지로 my_list[::-2]은 리스트의 처음부터 끝까지 간격 -2 단위로 슬라이싱한다.
my_list[::-3]은 리스트의 처음부터 끝까지 간격 -3 단위로 슬라이싱한다.
나의 코드
def solution(array, commands):
answer = []
for com in commands:
splited_array = array[com[0]-1:com[1]]
#print(splited_array)
splited_array.sort()
answer.append(splited_array[com[2]-1])
return answer
다른 사람 코드
def solution(array, commands):
return list(map(lambda x:sorted(array[x[0]-1:x[1]])[x[2]-1], commands))
?^^
이걸 이렇게 푼 사람은 뭘까요?
어떻게 하면 이런 풀이가 생각이 날까요 ..?
Lamda
파이썬 개발자들이 매개변수로 함수를 전달하는 번거로움을 줄이기 위해 함수를 함수이름 없이 선언하기 위해 도입한 개념이 lamda 입니다.
람다 함수는 다음과 같이 간단한 표현식을 만들 수 있습니다.
lambda 매개변수 : 매개변수를 이용한 리턴 값
예를 들어, 제곱을 구하는 함수를 만드는 경우를 생각해봅시다.
아래와 같이 우리가 잘 알고 있는 def를 이용하여 square_number()라는 함수를 만들어 사용하는 것이 일반적입니다.
def square_number(x):
return x * x
하지만 람다(lamda) 함수를 사용하면 lamda x : x * x 처럼 함수의 이름이 필요없으며 return 키워드를 따로 쓰지 않아도 함수처럼 선언하고 사용이 가능합니다.
(lambda x : x * x)(3)
or
square = lambda x : x * x
square(5)
또한 람다함수는 여러개의 매개변수를 사용하는 것도 가능하며, 특정 조건만 선택하는 것도 가능합니다.
#x와 y를 더하여 return
lambda x,y : x + y
#x가 2보다 크면 True return
lambda x : x > 2
람다는 함수를 매개변수로 전달하는 표준함수인 map() 함수, filter() 함수 등과 같이 사용할 경우, 그 효과가 극대화됩니다.
map() 함수는 리스트의 요소를 하나씩 꺼내어 함수에 넣고 리턴된 값으로 새로운 리스트를 만들어주는 함수입니다.
filter() 함수는 리스트의 요소를 함수에 넣고 리턴 값이 True 인 것만 리스트로 만들어주는 함수입니다.
map(함수, 리스트)
filter(함수, 리스트)
따라서 각 매개변수의 함수 자리에 lambda를 사용한다면, 코드가 굉장히 간단해집니다.
원래 리스트의 각 요소들을 제곱하여 새로운 리스트를 만드는 코드를 작성해보면 다음과 같습니다.
list = [1,2,3,4,5]
new_list = map(lambda x : x*x , list)
print(new_list)
print(list(new_list))
>> map object at 0x06DFC
>> [1,4,9,16,25]
이 때 처음 출력 값은 의도한대로?의 리스트가 출력되지 않습니다.
이른 map 함수의 결과 물이 제너레이터(Generator) 이기 때문입니다. 여기서 제너레이터란 내부의 데이터가 실제 메모리에 용량을 차지하는 것이 아니고 호출하기 전까지는 가상의 값만 가지고 있는 형태입니다. 따라서 list() 함수를 이용하여 강제로 리스트 자료형으로 변환하여 출력하였습니다.
추가로 람다를 자주 볼 수 있는 곳이 리스트를 정렬할 때 사용하는 sorted() 함수입니다.
sorted() 함수는 리스트를 정렬하여 새로운 리스트로 만드는 내장 함수입니다. sorted 함수는 매개변수로 key 함수를 사용할 수 있는데, key 매개변수의 값은 단일 인자를 취하고 정렬 목적으로 사용할 키를 반환하여야합니다.
정렬의 기준이 되는 key에 람다 표현식을 이용할 수가 있습니다.
예를 들어, [과일 이름, 개수]를 요소로 가지고 있는 이차원 리스트를 과일 이름으로 정렬해봅시다.
아래의 예제에서 x[0]은 과일 이름을 기준으로 정렬하기 위한 것이고, x[1]로 설정을 변경하면 과일 이름 대신 리스트의 두번째 요소인 개수로 정렬됩니다.
list_in = [['Orange',4],['Banana',7],['Kiwi',2],['Apple',5]]
sorted(list, key=lambda x : x[0])
* 다음의 글을 참고하여 작성하였습니다.
'Algorithm > 프로그래머스' 카테고리의 다른 글
| [프로그래머스] -그리디. 가장큰수 (0) | 2023.05.03 |
|---|---|
| [프로그래머스] - 정렬. 가장큰수 (0) | 2023.04.21 |
| [프로그래머스] - 스택/큐. 기능개발 (0) | 2023.03.06 |
| [프로그래머스] - 스택/큐.같은 숫자는 싫어 (0) | 2023.03.06 |



