
minzzl
[논문번역]Additive increase adaptive decrease congestion control: a mathematical model and its experimental validation 본문
[논문번역]Additive increase adaptive decrease congestion control: a mathematical model and its experimental validation
minzzl 2023. 3. 11. 15:55안녕하세요 ...
오늘은, AIAD 방식에 대해 알아보겠습니다람쥐
westwood+ 에 AIAD 방식이 쓰였다는데 ...
왜 !
관련 한국 레퍼런스가 업슴니까요 ......
한국 논문은 왜 !!!!
제대로 소개를 안해줌니까 !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Abstraction
네트워크가 명시적인 피드백을 제공할 수 없는 TCP/IP의 기본 종단 간 설계 원칙으로 인해 오늘날 TCP 혼잡 제어 알고리즘은 추가 증가 곱셈 감소(AIMD) 알고리즘을 구현합니다. AIMD 메커니즘이 종단 간 혼잡 제어 안정성의 핵심이라는 것은 널리 알려져 있습니다. 이 백서에서는 추가 증가 적응형 감소(AIAD)라고 부르는 새로운 메커니즘에 대해 설명합니다. 적응형 감소 메커니즘의 핵심 개념은 혼잡이 발생한 시점에 사용 가능한 대역폭에 맞춰 혼잡 창 감소를 조정하는 것입니다. AIAD 패러다임의 구현으로 Westwood++ TCP를 제안하고, 비교를 위해 AIMD 메커니즘의 예로 Reno TCP를 고려합니다. AIAD 메커니즘의 처리량에 대한 수학적 모델을 도출하여 Westwood++가 안정적이고 Reno에 친화적이며 대역폭 사용의 공정성을 높인다는 것을 보여줍니다. 이론적 모델의 유효성을 확인하기 위해 인터넷 측정값을 보고합니다.
-> AIAD 패러다임과 기존 혼잡제어 알고리즘과 비교
1. Introduction
인터넷의 안정성을 위해서는 Flow가 사용 가능한 대역폭에 맞게 입력 속도를 조정하기 위해 어떤 형태의 종단 간 혼잡 제어를 사용해야 합니다. TCP 혼잡 제어는 1980년대 후반 인터넷이 혼잡 붕괴를 경험한 후 Van Jacobson에 의해 인터넷에 도입되었습니다[1], [2]. 네트워크가 명시적인 피드백을 제공할 수 없는 블랙박스[4], [5], [8]인 TCP/IP의 근본적인 종단 간 설계 원칙으로 인해 TCP 혼잡 제어 알고리즘은 덧셈 증가 곱셈 감소 패러다임(AIMD-Additive Increase Multiplicative Decrease Paradigm)을 따라 설계되었습니다[17]. 가산적 증가 단계는 네트워크 가용 대역폭에 도달하여 혼잡이 발생할 때까지 흐름 입력 속도를 점진적으로 증가시키는 것을 목표로 합니다. 발신자는 중복 승인(DUPACK)을 수신하거나 타임아웃이 만료되면 혼잡을 인지하게 됩니다. 그런 다음 가벼운 혼잡(예: DUPACK 3개)에는 혼잡 창을 절반으로 줄이고, 심한 혼잡(예: 타임아웃)에는 혼잡 창을 1개로 줄임으로써 반응합니다. 이 동작은 혼잡 후 입력 속도를 줄이는 것을 목표로 하는 곱셈 감소 단계입니다.
이 논문에서는 혼잡이 발생한 후 혼잡 발생 시 사용되는 대역폭을 고려하여 혼잡 윈도우를 적응적으로 설정하는 새로운 메커니즘을 제안합니다. 우리는 이 메커니즘을 추가적 증가 적응적 감소(AIAD-Additive Increase Adaptive Decrease)라고 부릅니다.
Vegas TCP는 AIMD 패러다임에서 부분적으로 벗어난 혼잡 제어 알고리즘의 첫 번째 중요한 사례로 간주될 수 있습니다 [12], [14]. 실제로, 혼잡 회피 중에 Vegas는 가산 증가 가산 감소(AIAD-additive increase additive decrease) 메커니즘을 활용합니다 [10]. AIMD 패러다임에서 부분적으로 벗어난 제어 알고리즘의 또 다른 예로는 정교한 종단 간 대역폭 추정을 사용하여 가벼운 혼잡 후 제어 창을 설정하는 Westwood TCP [3]가 있습니다. Vegas와 Westwood TC 모두 타임아웃 후 표준 승수 감소 동작을 유지합니다.
이 백서에서는 AIAD 패러다임의 완전한 활용을 기반으로 하는 Westwood++ TCP를 제안합니다. 이 백서의 주요 내용은 Westwood++의 처리량에 대한 간단한 확률론적 모델로, 이를 통해 Westwood++가 (1) 안정적이고, (2) Reno에 친화적이며, (3) 네트워크 사용의 공정성을 높인다는 것을 보여줍니다.
제안된 방정식 모델을 검증하기 위해 인터넷에서 Westwood++를 테스트하고 Reno TCP와 비교합니다. 실험 결과, 이 모델은 11.7%에서 43.9%의 평균 오차 범위 내에서 Westwood++의 처리량을 예측하며 Reno가 Westwood++보다 약간 작은 처리량을 얻는다는 것을 보여줍니다.
이 논문은 다음과 같이 구성됩니다. 섹션 2에서는 Westwood++ TCP의 방정식 모델을 개발하고, 섹션 3에서는 인터넷 측정을 통해 모델을 검증하고 Reno TCP와의 비교를 제공하며, 마지막 섹션에서는 결론을 도출합니다.
-> AIMD 방식의 한계와 AIAD를 사용한 vegas , westwood
2. Westwood++ TCP
이 섹션에서는 Westwood++TCP에 대해 설명하고 정상 상태 처리량에 대한 수학적 모델을 개발합니다.
2.1 Westwood++ TCP
먼저 westwood TCP 알고리즘[3]을 간략히 다시 살펴본 다음 웨스트우드++를 소개합니다.
- TCP 연결은 다음과 같은 변수로 특징지어집니다:
- (cwnd) 혼잡 윈도우,
- (ssthresh) 슬로우 스타트 임계값,
- (RTT) 연결의 왕복 시간,
- (RTTmin) 발신자가 측정한 최소 왕복 시간,
- (Seg size) 전송된 세그먼트의 크기.
westwood TCP의 주요 아이디어는 반환되는 ACK의 비율을 측정하고 로우패스 필터링하여 TCP 연결에서 사용 가능한 대역폭 B를 엔드투엔드 추정하는 것입니다. 그런 다음 이 추정치를 사용하여 아래 설명된 대로 혼잡 에피소드 후 혼잡 창과 느린 시작 임계값을 적절하게 설정합니다:
- 발신자가 3개의 DUPACK을 받은 경우:

- TIMEOUT
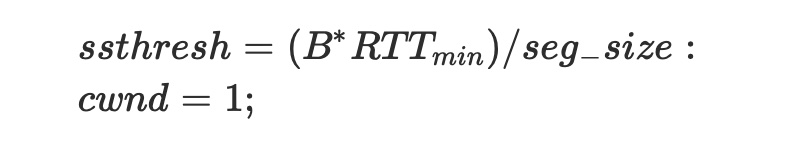
- ACK를 성공적으로 수신하면 TCPW는 Reno 알고리즘에 따라 cwnd를 증가
웨스트우드++ TCP의 아이디어는 타임아웃 이후에도 대역폭 추정치를 활용한다는 것입니다. 실제로 ACK의 리턴 흐름을 기반으로 하는 대역폭 추정 메커니즘은 여러 개의 ACK가 손실될 때 백오프를 보장합니다. 즉, 단계 (a)에서 사용된 대역폭 추정은 심한 혼잡에도 충분히 대응할 수 있습니다. 따라서 웨스트우드++ 알고리즘은 (a)와 (b)를 통합함으로써 다음과 같이 AIAD 패러다임을 완전히 활용합니다:
(a) Dupack 3개를 받거나 타임아웃이 만료된 경우:
(b) ACK를 성공적으로 수신하면 TCPW는 Reno 알고리즘에 따라 cwnd를 증가
AIAD 메커니즘은 추가 증가 곱셈 감소 알고리즘(AIMD)의 안정성 속성을 개선할 수 있다는 점에 주목해야 합니다. 실제로 적응형 감소 단계는 혼잡이 있을 때 창이 충분히 감소하도록 보장하는 반면, Reno의 절반 감소로는 충분하지 않을 수 있습니다.
-> Westwood Algorithm 소개 및 혼잡제어 방식 설명
2.2 A Stochastic Model of Westwood++ Throughput
이 섹션에서는 웨스트우드++ 처리량에 대한 수학적 모델을 개발합니다. 모델을 도출하기 위해 우수한 논문 [7]에서 개발된 것과 유사한 논증을 따릅니다.
정리 1
Westwood++ TCP 플로우를 고려하고 세그먼트의 드롭 확률은 p, 플로우에 사용 가능한 대역폭은 B, 평균 왕복 시간은 RTT, 최소 왕복 시간은 RTTmin이라고 가정해 봅시다. rWest를 흐름의 정상 상태 평균 처리량으로 설정하면 다음과 같이 유지됩니다:
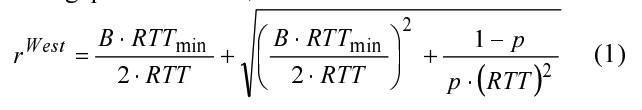
증명
혼잡 윈도우는 ACK 수신 시 업데이트됩니다. 발신자가 ACK를 수신할 때마다 혼잡 윈도우는 1/cwnd만큼 증가하지만, 세그먼트 손실 후에는 혼잡 윈도우가 B⋅RTTmin과 동일하게 설정되므로 혼잡 윈도우의 변화는 B⋅RTTmin-cwnd가 됩니다. 따라서 혼잡 윈도우 Δcwnd의 변화는 다음과 같은 확률 함수를 갖는 이산 랜덤 변수입니다:
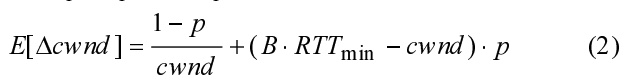
그러면 업데이트 단계당 예상되는 혼잡 기간 cwnd의 증가율이 계산됩니다:
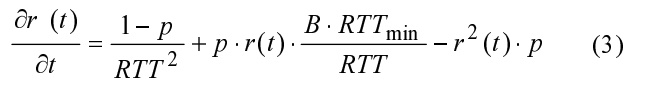
방정식 (3)은 분리 가능한 변수 미분 방정식으로 다음과 같이 쓸 수 있습니다:

각 멤버를 통합하면 다음과 같은 솔루션을 얻을 수 있습니다.

그러면 Westwood++의 정상 상태 처리량은 다음과 같이 계산됩니다.

3. Model Based Evaluation of Westwood++
이 섹션의 목표는 Westwood++의 안정성, 공정성, 우호성을 분석하고 각각의 처리량 방정식 모델을 사용하여 Reno TCP와의 비교를 개발하는 것입니다. 마지막으로 인터넷 측정값을 사용하여 Westwood++의 모델을 검증합니다.
3.1 Stability and Full Bandwidth Utilization
먼저 Westwood++가 안정적이라는 것, 즉 정상적인 상태의 입력 속도가 사용 가능한 대역폭 B에 의해 결정된다는 것을 보여줍니다.
결론 1
웨스트우드++ 제어 알고리즘은 안정적입니다:
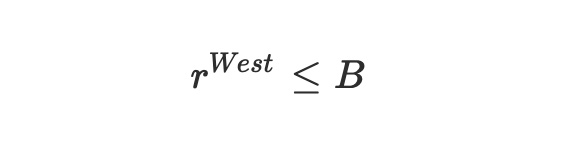
증명
방정식 (1)에서 rWest는 결코 B보다 클 수 없다고 주장할 수 있습니다. 사실, 모순에 의해 rWest>B라고 가정해 봅시다. 이 가정은 혼잡 붕괴로 이어져 드랍 확률 p가 최대 1까지 증가하게 됩니다. 따라서 식 (1)에서 rWest=B⋅RTTmin/RTT가 됩니다. 혼잡 상태에서는 RTTmin<RTT가 되므로 rWest<B가 되며, 이는 가정과 모순됩니다. 따라서 rWest≤B라는 결론을 내릴 수 있습니다.
결론 2
B^를 B의 추정치라고 하자. 웨스트우드++ 처리량은 경계를 만족합니다:

where 0<α≤1.
방정식 (1)에서 rWest>α⋅B^를 쉽게 알 수 있으며, 여기서 α=RTTmin/RTT ≤ 1입니다.
-> westwood 의 안정성과 대역폭 효과적 사용
3.2. Fairness and Friendliness of Westwood++
방정식 (1)은 주어진 용량 B의 함수로서 처리량을 제공합니다. 그러나 실제 네트워크에서는 사용 가능한 대역폭 B를 알 수 없습니다. 따라서 종단 간 대역폭을 추정하는 메커니즘을 사용해야 합니다. 기본 아이디어는 반환되는 ACK의 흐름을 통해 사용 가능한 대역폭을 추정하는 것입니다. 지연 및 ACK 압축으로 인해 반환되는 ACK의 흐름은 적절한 방식으로 저역 통과 필터링되어야 합니다 [3], [9], [11], [13], [15], [18], [19]. 3]에서는 발신자가 ACK를 수신할 때마다 사용 가능한 대역폭 샘플 bk=dk/(tk-tk-1)=dk/Δk가 계산됩니다, ACK에 의해 승인된 데이터의 양 dk는 적절한 카운팅 절차에 의해 결정되며, 샘플 bk는 시간 가변 필터 b^k=2τf-Δk2τf+Δkb^k-1+Δkbk+bk-12τf+Δk(여기서 τf는 필터 시간 상수입니다(일반적인 값은 τf=0입니다. 5초)입니다. 이 논문에서는 [3]에서 사용된 필터를 약간 수정한 버전을 사용하는데, 그 이유는 이 필터가 ACK 압축[15]으로 인해 가용 대역폭을 과대평가하기 때문입니다. 이 문제를 극복하기 위해 매 RTT마다 대역폭 샘플을 계산합니다. 보다 정확하게는 마지막 RTT 동안 승인된 모든 데이터 dk를 계산하여 대역폭 샘플 bk=dk/Δk를 계산하며, 여기서 Δk는 마지막 RTT입니다. 에일리어싱 효과[6]를 피하기 위해 Δk>τf/4인 경우, 도착 시간 Δk=τf/4로 도착하는 가상 샘플 bk에 대해 N=int(4⋅RTT/τf) 2를 사용하여 보간하고 다시 샘플링합니다.
유량 보존 원칙으로 인해 추정기는 입력 속도 cwnd/RTT에 가까운 B 값을 제공한다는 점에 주목할 필요가 있습니다. 추정치에 대한 근사치 B=cwnd/RTT를 가정하면 다음과 같은 결과를 얻을 수 있습니다.
정리 2
대역폭 추정치 B=cwnd/RTT를 사용하는 Westwood++의 정상 상태 처리량은 다음과 같습니다.
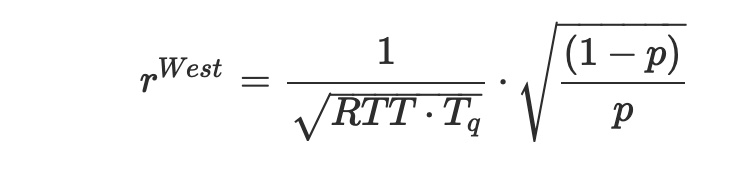
여기서 Tq=RTT-RTTmin은 연결 세그먼트가 경험한 평균 대기 시간입니다.
증명
사용 가능한 대역폭을 다음과 같이 추정합니다:
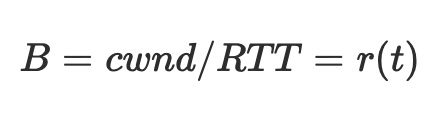
식 (8)을 식 (3)에 대입하면 다음과 같은 미분 방정식을 구할 수 있습니다:

변수를 분리하면 방정식 (9)는 다음과 같이 쓸 수 있습니다:

그리고 각 구성원을 통합하여 솔루션을 제공합니다:

여기서, C는 초기 조건에 따라 달라집니다. 그러면 t→∞에 대한 정상 상태 처리량 (7)을 구할 수 있습니다.
이제 웨스트우드++ 처리량 (7)을 [16]에 보고된 리노 처리량과 비교할 준비가 되었습니다:

여기서 T0은 타임아웃입니다. p<<1일 때, (12)의 근사치는 다음과 같습니다([16] 참조).

친숙도와 관련하여 (7)과 (13)을 비교하면 Westwood++와 Reno의 처리량이 모두 1/√p에 의존한다는 것을 알 수 있습니다. 즉, Westwood++가 Reno에 친숙하다는 것을 알 수 있습니다. 또한 (7)에서 RTT가 다른 플로우는 동일한 평균 대기 시간 Tq를 경험한다는 것을 알 수 있습니다. 따라서 Westwood++의 처리량은 왕복 시간에 1/√RTT로 의존하는 반면 Reno의 처리량은 1/RTT로 의존합니다. 따라서 공정성과 관련하여 Westwood++는 RTT가 다른 플로우 간에 네트워크 용량을 공정하게 공유한다는 결론을 내릴 수 있습니다.
-> westwood 수학적 모델을 통한 결론 도출 : Reno에 친숙, 네트워크 용량을 공정하게 공유
3.3. Modeling the Impact of Window Limitation
지금까지는 cwnd 크기에 제한이 없다고 가정했습니다. 이 하위 섹션에서는 혼잡 윈도우 값에 대한 최대 제한이 있다는 가정 하에 Westwood++ 처리량을 모델링하는 것을 목표로 합니다. 따라서 데이터 전송 중에 cwnd가 최대 값에 도달하여 손실이 발생한 시점에 예상되는 가용 대역폭이 B=WMAX/RTT와 같다고 가정합니다. 따라서 손실이 발생한 후 cwnd는 cwnd=B⋅RTTmin=WMAXRTTmin/RTT로 설정됩니다. 이 가정 하에서 그림 1에 표시된 cwnd의 시간 영역 동작을 구할 수 있습니다.
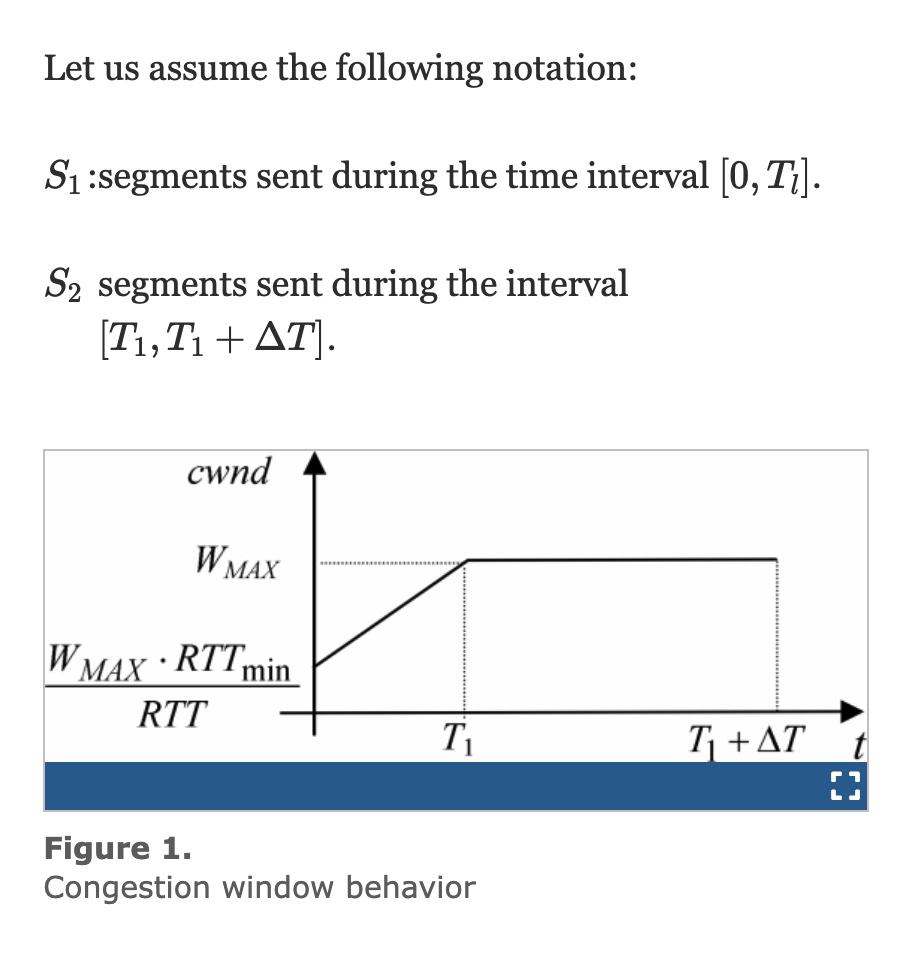
그림 1에서 다음과 같습니다.
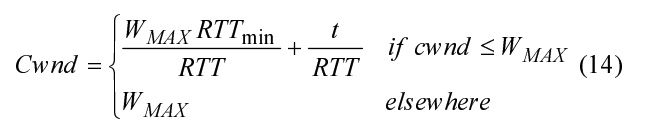
방정식 (14)에서
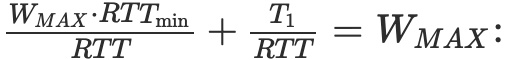
관계를 사용하여 T1을 계산할 수 있습니다:

r=cwnd/RTT가 연속 입력 속도임을 고려하면, 시간 간격 [0,Tl] 동안 전송되는 세그먼트 수는 다음과 같이 주어집니다.
.
.
.
3.4. Empirical Validation of the Model
제안된 방정식 모델을 검증하기 위해 인터넷에서 Westwood++를 테스트합니다. 세 대의 서로 다른 서버를 사용하여 30개의 ftp 업로드를 수행합니다. 우리 클라이언트는 Linux 2.2.20 버전의 Westwood++ TCP를 실행하며 이탈리아 남부에 위치한 "Politecnico di Bari"에 있습니다. 첫 번째 서버는 이탈리아 북부의 "Politecnico di Torino"에, 두 번째 서버는 스웨덴의 "Uppsala University"에, 세 번째 서버는 캘리포니아 대학교 로스앤젤레스에 있습니다. 2001년 11월 17일에 각 서버에서 30회 연속 업로드에 대해 4M바이트를 전송했습니다. 각 전송이 끝날 때마다 (1) 대역폭 추정치 B의 평균값, (2) 재전송된 세그먼트 수와 전송된 총 세그먼트 수 사이의 비율로 계산된 드롭 확률 p, (3) 평균 RTT 및 (4) 최소 RTTmin을 측정했습니다. 그런 다음 식 (22)와 (7)에 의해 예측된 평균 처리량을 계산하고 이를 실제 측정된 처리량과 비교했습니다.
각 전송에 대해 상대 오차를 다음과 같이 계산했습니다.
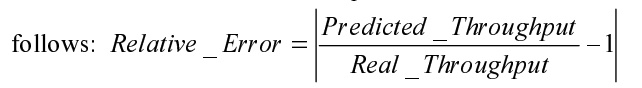
로 설정하고 각 서버에 대해 다음과 같이 정규화된 오류를 계산합니다:

웨스트우드++와 리노에 대한 수집된 데이터는 표 I, II, III, IV에서 확인할 수 있습니다. WMAX에 의해 연결이 제한되지 않았음을 알 수 있었습니다.
표 I, II, III에서 방정식 모델(22)을 사용하여 얻은 정규화된 오차는 토리노에 위치한 서버의 경우 37.5%, 스웨덴에 위치한 서버의 경우 44%, 로스앤젤레스에 위치한 서버의 경우 11.7%임을 확인할 수 있습니다. 이러한 오차는 [16]에서 Reno 방정식 모델(23)을 검증하기 위해 보고된 것과 비슷한 수준입니다. 근사 방정식 모델 (7)을 사용하면 정규화된 오류는 토리노 서버의 경우 59.9%, 스웨덴 서버의 경우 92%, 로스엔젤레스 서버의 경우 41.7%입니다. 16]에서 방정식 모델 (13)을 사용하여 예측했을 때 TCP Reno의 처리량에 대해 비슷한 오류가 발견되었습니다.
표 IV는 Reno 연결에 대한 측정값을 보고합니다. 데이터에 따르면 Reno는 Westwood++보다 약간 더 작은 처리량을 얻습니다.



4.Conclusions
저희는 인터넷 혼잡 제어를 위한 새로운 웨스트우드++ 알고리즘을 제안했습니다. 수학적 모델링을 통해 Westwood++ TCP가 안정적이고 Reno TCP에 비해 공정성을 개선하며 Reno TCP에 친화적이라는 것을 증명했습니다. 마지막으로 이 모델은 실시간 인터넷 측정을 통해 검증되었습니다.
'논문 > QUIC' 카테고리의 다른 글
| QUIC 톺아보기 (1) (1) | 2023.07.10 |
|---|---|
| [논문번역]Performance Evaluation and Comparison of Westwood+, New Reno, and Vegas TCP Congestion Control (0) | 2023.03.13 |
| [논문번역] Performance Analysis of TCP Congestion Control Algorithms (0) | 2023.03.08 |
| Network Simulator - NS-3 소개, 그리고 설치 방법 (0) | 2023.03.07 |



